
Tutoriel découverte de Snowflake
Dans ce tutoriel, nous allons vous guider pour faire vos premiers pas avec Snowflake. Nous allons créer notre premier entrepôt (warehouse), notre première base de données Snowflake, et explorer les différents rôles tout en manipulant les fonctionnalités de base nécessaires pour débuter avec Snowflake.
Prérequis :
- Disposer d’un accès à la plateforme snowflake
Présentation de snowflake :
Snowflake est une plateforme de gestion de données basée sur le cloud, conçue pour stocker et analyser d’importants ensembles de données de manière scalable et flexible. Elle offre une architecture de données unique, permettant la séparation du stockage et du traitement, ce qui simplifie le dimensionnement des ressources en fonction des besoins. Grâce à son approche de data warehousing cloud-native, Snowflake facilite le partage sécurisé des données entre différentes équipes et organisations, tout en offrant des fonctionnalités avancées d’analyse et de requêtage SQL. Son architecture distribuée et sa capacité à gérer des données semi-structurées en font une solution prisée pour les entreprises cherchant à optimiser leurs opérations analytiques dans le cloud.
Découverte de la plateforme snowflake :
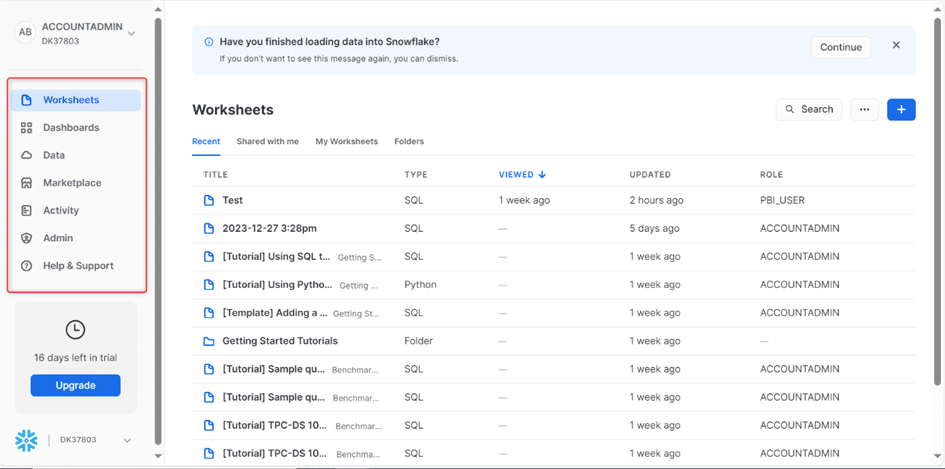
L’onglet « Worksheets » regroupe les différents scripts que nous allons écrire afin de créer nos bases de données, notre entrepôt de données, ainsi que pour gérer nos différents utilisateurs, etc. Nous avons la possibilité de choisir le langage que nous souhaitons utiliser pour nos scripts.
Dans notre cas, nous avons opté pour un script SQL. Voici un exemple de notre script.
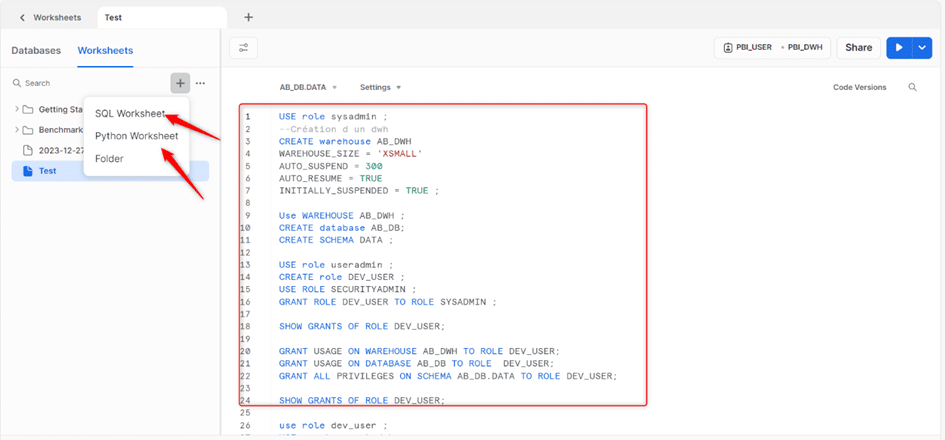
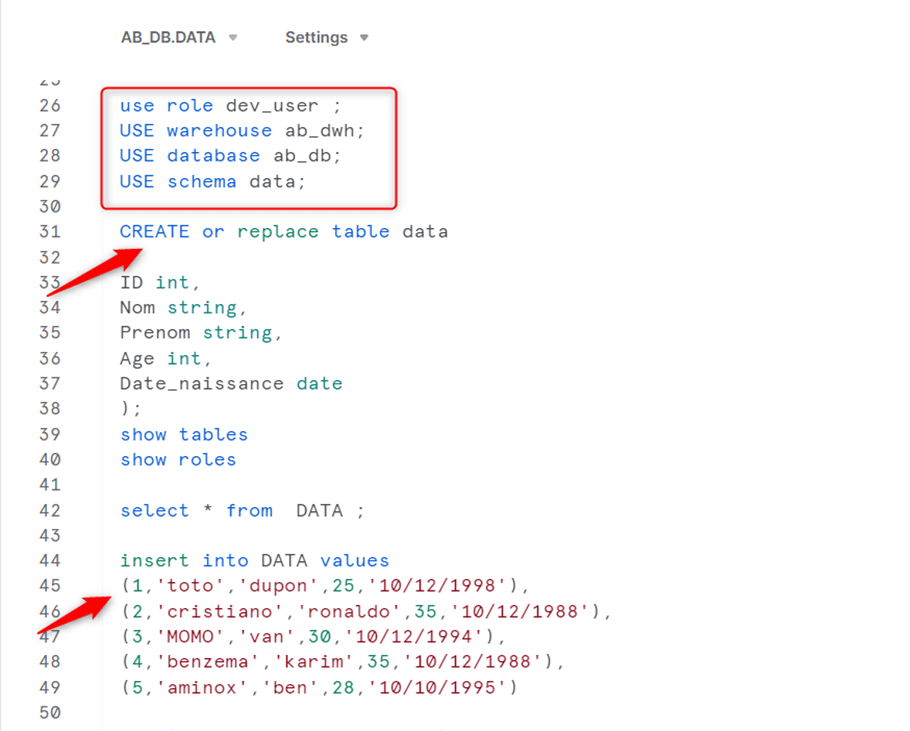
Pour exécuter notre code, on clique sur la flèche bleue en haut à droite. On peut exécuter l’ensemble du code ou sélectionner une portion du code et n’exécuter que cette dernière. Ce script nous permet de créer un entrepôt virtuel, qui est un cluster de ressources de calcul dans Snowflake, où nous allons exécuter nos différentes requêtes. Nous utilisons le rôle sysadmin, qui a tous les droits nécessaires pour créer nos ressources. Ensuite, nous créons notre entrepôt avec les paramètres nécessaires : nom (AB_DWH), taille (XSMALL), auto_suspend (300 secondes, le nombre de secondes avant la suspension de notre entrepôt en cas d’absence d’activité), autoresume (true, permettant de rallumer l’entrepôt en cas de requête), initial_suspend (true, permettant de donner le statut suspendu à notre entrepôt par défaut dès la création).
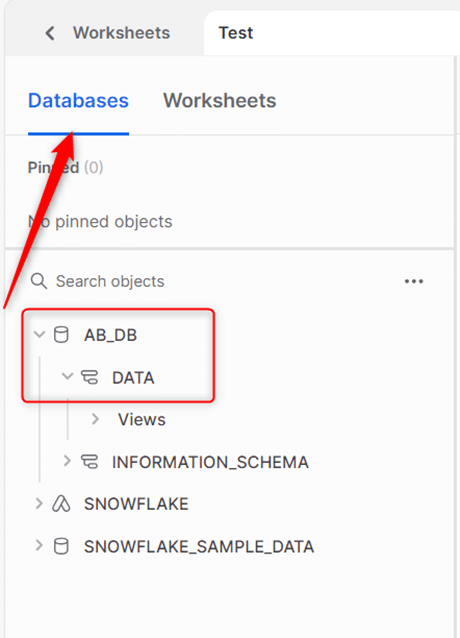
Notre entrepôt est créé, nous allons donc l’utiliser pour créer notre base de données. Pour cela, nous avons la ligne « USE WAREHOUSE AB_DWH ». Juste après, nous créons notre base de données « AB_BD » ainsi que notre schéma « DATA ». Nous passons à l’onglet Database pour vérifier la présence de notre base et de notre schéma. Nous constatons que les bases « AB_DB » et « DATA » sont bien présentes.
Pour l’utilisation de nos ressources, la bonne pratique impose la création de plusieurs rôles. Ainsi, nous allons créer deux rôles : un rôle « développeur » qui autorisera les personnes à manipuler les ressources de notre entrepôt (création de tables, alimentation et mise à jour de tables), et un deuxième rôle « powerbi user » qui permettra la lecture des données de notre entrepôt.
Pour l’attribution des droits à un rôle, nous devons utiliser le rôle « securityadmin ».
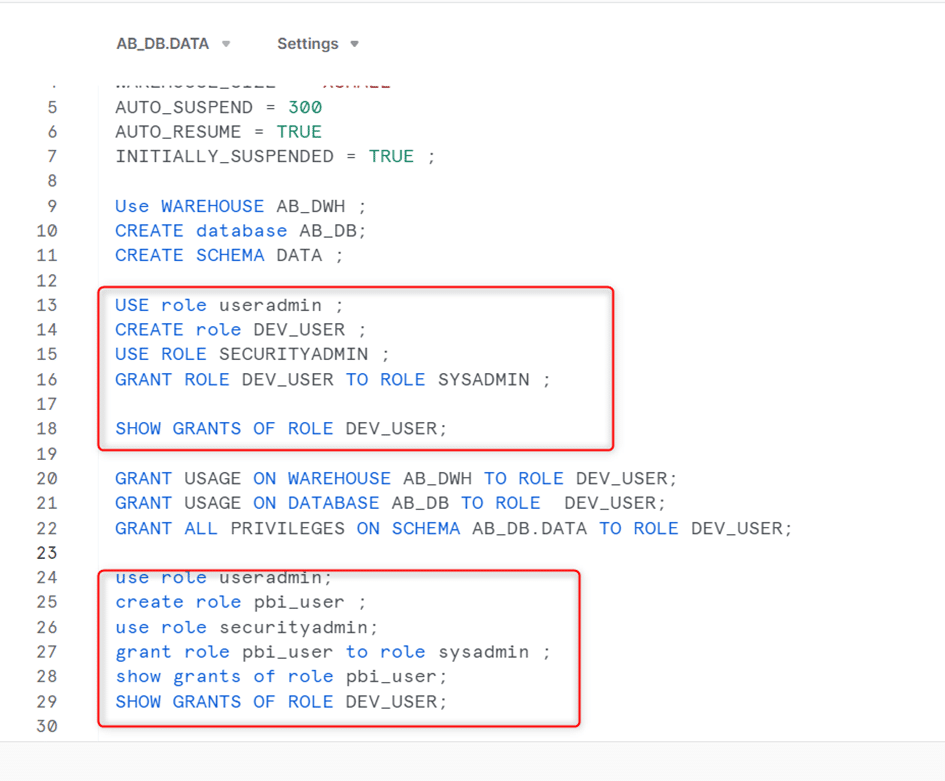
Pour visualiser les droits d’un rôle on exécute la ligne SHOW GRANTS OF ROLE.

Notre rôle a tous les droits nécessaires, on peut donc l’utiliser afin de créer et d’alimenter une table. On crée la table « Data », une simple table où nous allons stocker quelques informations, puis nous insérons des données dans cette table. Pour cela, nous spécifions notre contexte en choisissant le user avec lequel nous voulons exécuter l’opération, le datawarehouse et la base de données qui contiendront notre table.
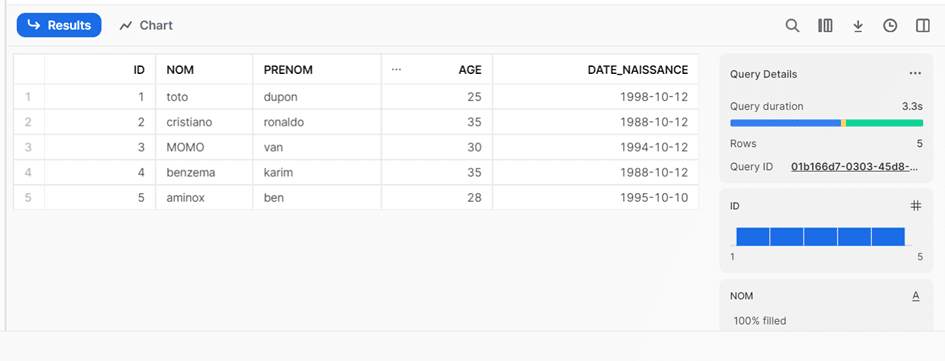
Pour insérer des données dans une table, plusieurs moyens sont disponibles : se connecter à un datalake et récupérer les données, utiliser un outil ETL tel que Talend, recourir à un fichier que l’on va uploader directement sur la plateforme Snowflake, ou bien effectuer une insertion avec un script en dur.
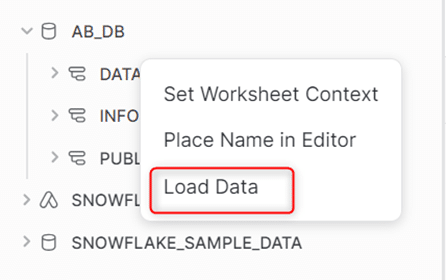
On peut également le faire en insérant des fichiers directement depuis la plateforme Snowflake. Dans l’onglet « Databases », on clique sur les trois points à côté du nom de la base de données, puis on sélectionne « Load Data ».
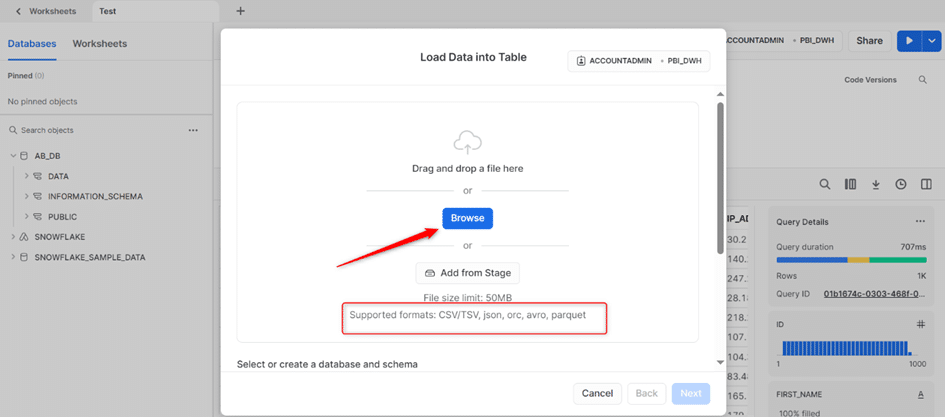
Une fenêtre s’affiche qui nous permet de glisser notre fichier ou de le récupérer depuis notre PC. Il faut noter qu’il y a une taille maximale pour les fichiers ainsi que des formats précis qui sont pris en charge, tels que les fichiers CSV, JSON, etc.

Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !