
Le SQL Endpoint du Lakehouse : La porte d’entrée SQL vers vos données Delta
Introduction :
Dans Microsoft Fabric, le Lakehouse combine les avantages d’un data lake (stockage flexible) et d’un data warehouse (analyse SQL). Face à la problématique récurrente d’accès aux données Delta pour les analystes métier — qui ne maîtrisent pas PySpark et pour qui la création d’un Warehouse séparé impliquerait duplication des données, coûts supplémentaires et complexité de gouvernance — Fabric génère automatiquement un SQL Endpoint lors de la création de chaque Lakehouse. Cette interface T-SQL native permet d’interroger directement les fichiers Delta sans configuration, sans duplication, et sans nécessiter de compétences en programmation Spark.
Workflow typique :
- Votre pipeline PySpark charge des données dans le Lakehouse (fichiers Delta)
- Fabric génère automatiquement le SQL Endpoint
- Les analystes peuvent requêter en T-SQL
- Power BI se connecte directement au SQL Endpoint
Capacités et évolutions du SQL Endpoint :
1.Environnement de requêtage enrichi : les notebooks T-SQL
Depuis septembre 2024, le SQL Endpoint propose un environnement de travail avancé via les notebooks T-SQL, passés en disponibilité générale en juin 2025.
Fonctionnalités clés :
- Cellules multiples et markdown : Documentez vos analyses directement dans le notebook

- Support multi-sources : Interrogez plusieurs Warehouses/SQL Endpoints dans un seul notebook
- Historique et monitoring : Accédez à l’historique complet de vos requêtes et suivez les performances

2.Visualisation automatique des résultats :
Le SQL Endpoint intègre une intelligence de visualisation qui analyse vos résultats de requêtes et suggère automatiquement les graphiques pertinents.
Fonctionnalités :
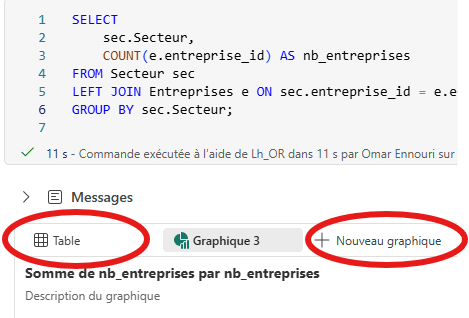
- Graphes natifs : Passez de la vue Table à la vue Graphique en un clic
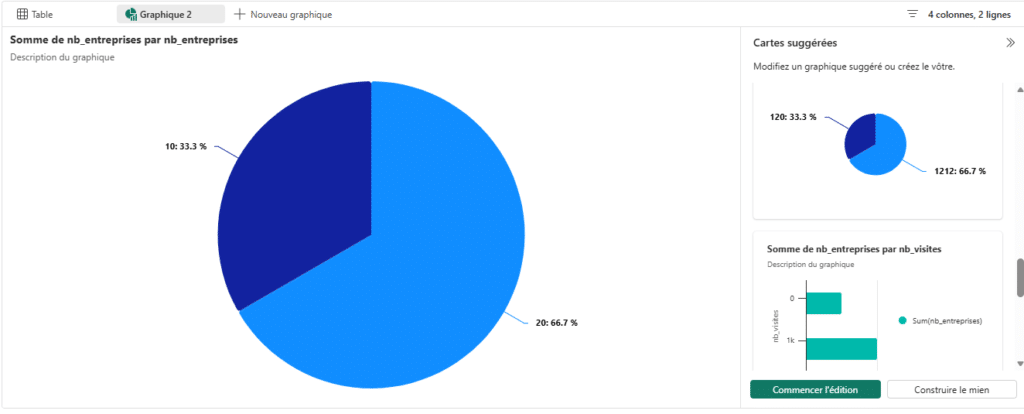
- Suggestions intelligentes : Fabric propose les types de graphiques adaptés (camembert, barres, courbes)
- Personnalisation : Éditez les visuels directement dans l’interface
- Export multi-formats : Sauvegardez vos graphiques en PNG, JPEG ou SVG
3. Export et intégration multi-formats
Le SQL Endpoint facilite le partage et l’intégration de vos résultats avec plusieurs options d’export.
Options disponibles :
- Excel : Intégration directe via « Ouvrir dans Excel »
- CSV : Téléchargement pour analyse externe ou archivage
- JSON / XML : Pour intégrations avec des APIs ou applications tierces
- Tableau persistant : Crée une vue dans le SQL Endpointe directement depuis vos résultats

SQL Endpoint vs Warehouse : Guide de décision
1.Quand utiliser le SQL Endpoint ?
- Besoin d’accès SQL en lecture pour analyse et reporting (SELECT, JOIN, GROUP BY..)
- Équipe mixte : Data Engineers (Python) + Analystes (SQL)
Cas d’usage concrets :
1. Reporting Power BI sans duplication Connectez Power BI directement au SQL Endpoint , pas de coût Warehouse supplémentaire.
2. Accès SQL pour profils non-techniques Vos analystes peuvent requêter les tables Delta via l’interface Fabric, sans connaître PySpark.
2.Quand créer un Warehouse ?
Optez pour un Warehouse si vous avez besoin de :
- Transformations complètes en T-SQL (INSERT, UPDATE, DELETE, MERGE)
- Procédures stockées , triggers ou fonctions SQL
- Architecture 100% SQL sans dépendance à Spark
Limites du SQL Endpoint (READ-ONLY)
Le SQL Endpoint ne supporte pas les opérations d’écriture :
-- ❌ Ces opérations échouent
INSERT INTO Visites VALUES (...);
UPDATE Salaries SET poste = 'Manager';
DELETE FROM Examens WHERE examen_id = 100;
CREATE TABLE nouvelle_table (id INT);Pourquoi ? Les fichiers Delta sont gérés par le moteur Spark. Pour modifier les données, utilisez un notebook PySpark ou un Warehouse.
Conclusion
Le SQL Endpoint du Lakehouse élimine la barrière entre Data Engineers (Spark) et analystes métier (SQL) en exposant automatiquement les fichiers Delta via une interface T-SQL, sans duplication ni configuration. En lecture seule, et enrichi par les récentes évolutions (notebooks, visualisations, exports), il constitue la solution native pour l’analyse et le reporting dans les architectures Spark-first. Le Warehouse reste réservé aux transformations SQL complètes (INSERT/UPDATE/DELETE).
Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !