
Extraire des données structurées avec la fonction gen_row_num_by_group()
Dans ce tutoriel, vous découvrez un exemple d’utilisation de la fonction gen_row_num_by_group(champs) sous Data Integrator pour extraire et organiser des données depuis une source Excel.
Prérequis :
- Data Integrator 4.2 SP7 installé avec IPS 4.2 SP3.
- Référentiel local crée.
- JOB crée sous le Designer de Data Integrator avec le référentiel local.
- Fichier Excel source « Financial sample.xlsx » : exemple de source contenant des données financières par pays et produit.
- Savoir créer un JOB avec un DataFlow et des composants sous le Designer de Data Integrator. Voir le tutoriel suivant.
- Savoir créer une source et une cible de données. Voir le tutoriel suivant pour l’import d’un fichier Excel et le tutoriel suivant pour éditer un format de fichier.
Voici un extrait du fichier Excel source utilisé, les colonnes qui vont être utilisées sont surlignées :
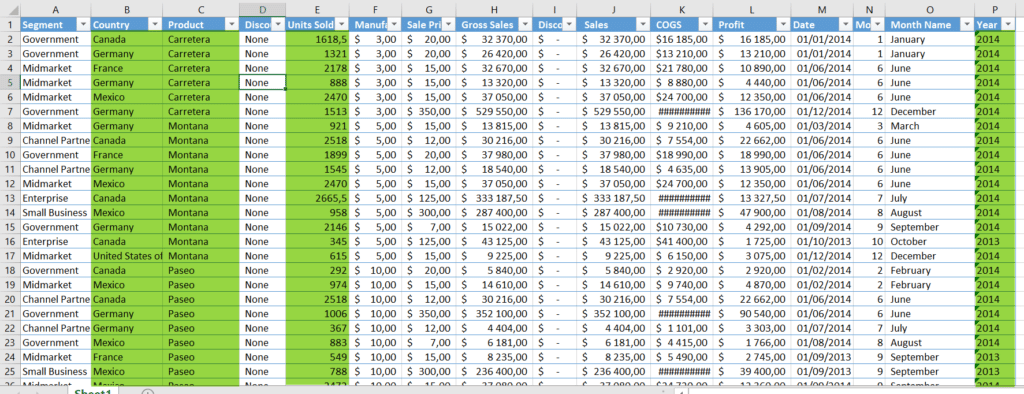
Nous allons pour l’année 2014 et chacune des régions, afficher les 3 produits les plus vendus avec leur quantité vendue (« Unit Sold ») agrégée sur l’année qui sera indiquée en entête de la cible. Nous afficherons le résultat dans un fichier CSV avec des champs séparés par des points virgule, ce qui permettra de réutiliser facilement les données cibles obtenues et de les afficher sous Excel.
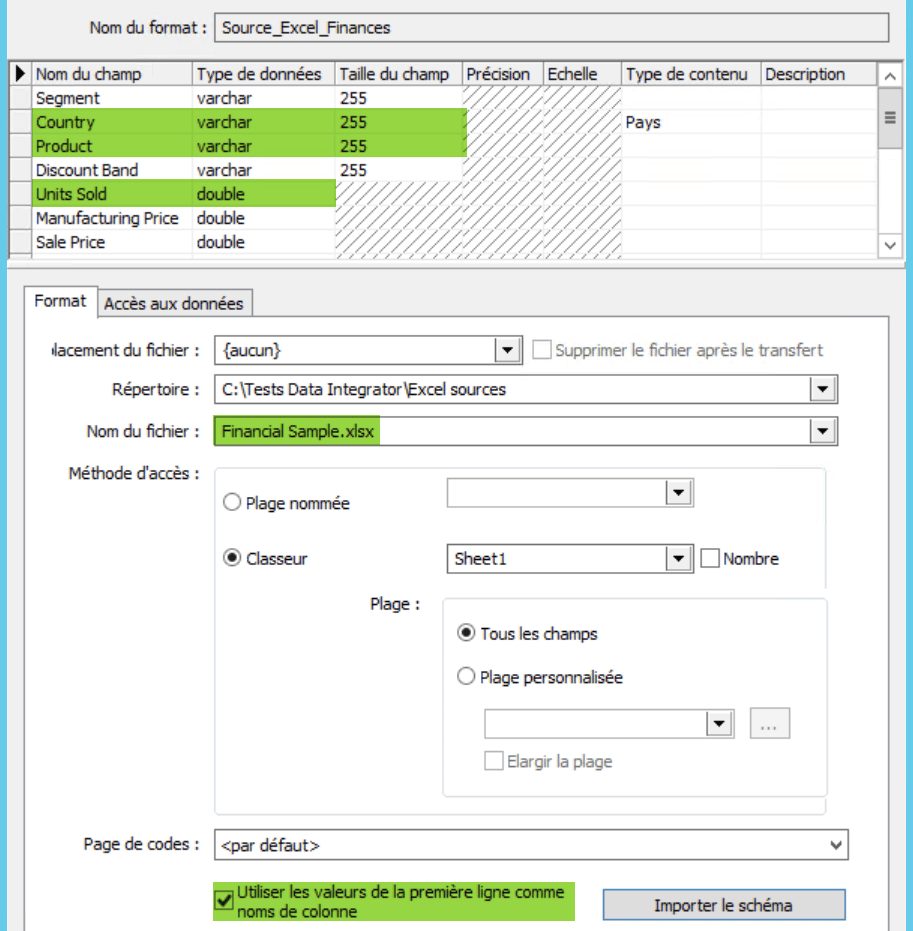
La première étape est d’importer le schéma de la source Financial sample.xlsx, ci – dessous vous pouvez voir la fenêtre d’import avec le nom des champs qui nous serons utiles. Pensez à cocher l’option en bas vous permettant d’utiliser la première ligne comme nom de colonne. Vous pouvez aller voir le tutoriel suivant pour en savoir plus sur l’import de fichiers Excel sous le Designer de Data Integrator.
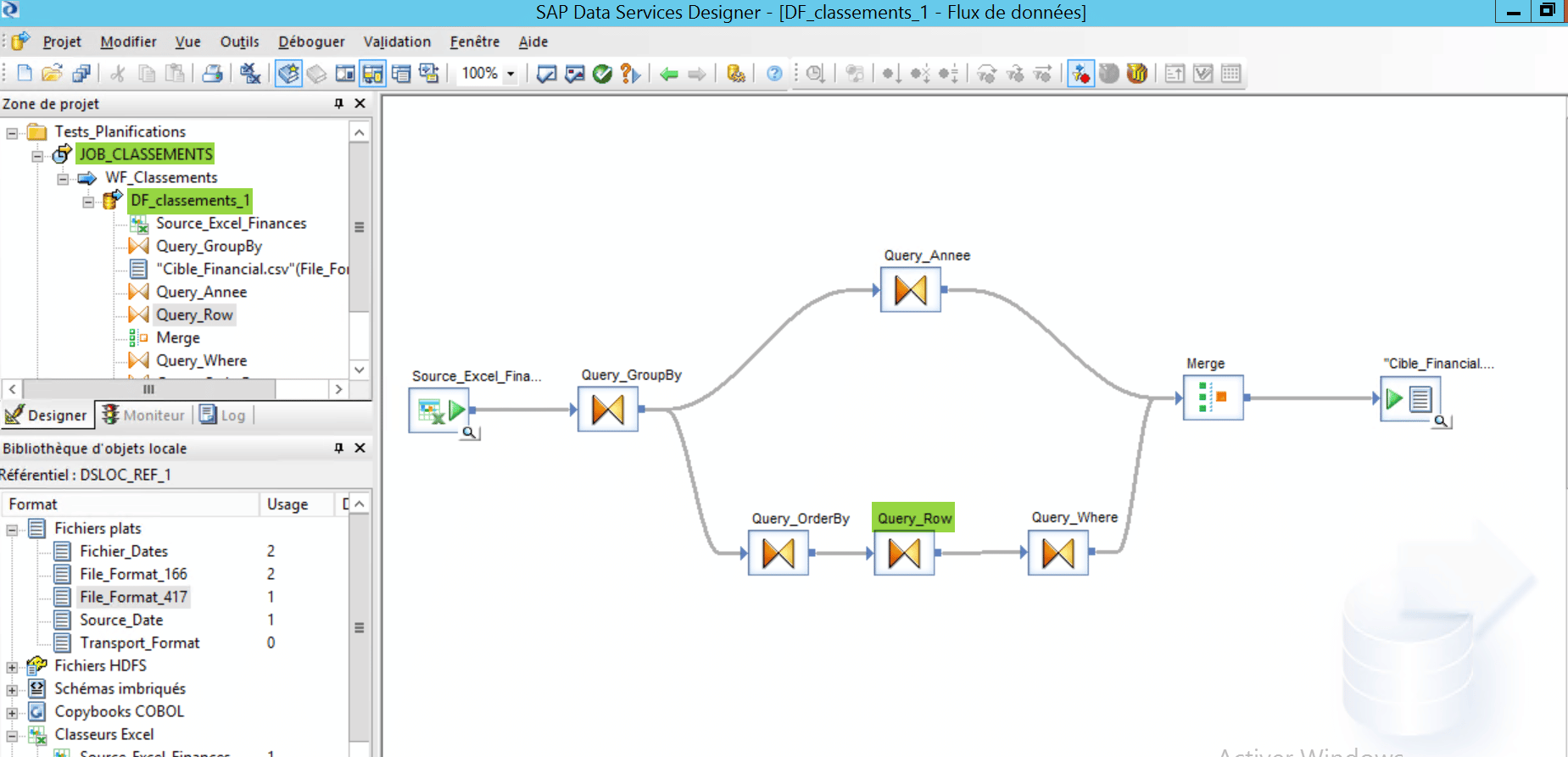
Ci – dessous vous pouvez voir le Dataflow DF_Classements_1 contenant le flux de traitement de notre JOB. Nous allons détailler étape par étape comment sont développés chacun des composants et le fonctionnement de l’ensemble. Le composant ou sera utilisé la fonction centrale de ce tutoriel (fonction gen_row_num_by_group) est le Query_Row :
Dans un premier temps paramétrez l’éditeur de format du fichier de destination Cible_Financial.csv avec son nom, son séparateur de champs (choisissez des points virgule) et de ligne et cochez « Non » dans « Ecrire l’entête de ligne » car nous allons écrire cette entête au sein d’un composant Data Integrator afin de la paramétrer :

Composant Query_GroupBy :
C’est la première étape de notre flux que vous pouvez voir ci – dessous. Vous pouvez voir à droite les champs qui vont nous intéresser pour la sortie, les colonnes « Région » et « Produit » avec leur mappage direct sur les entrées « Country » et « Product », ainsi que la colonne Somme_Vente dont nous expliquerons le mappage par la suite :
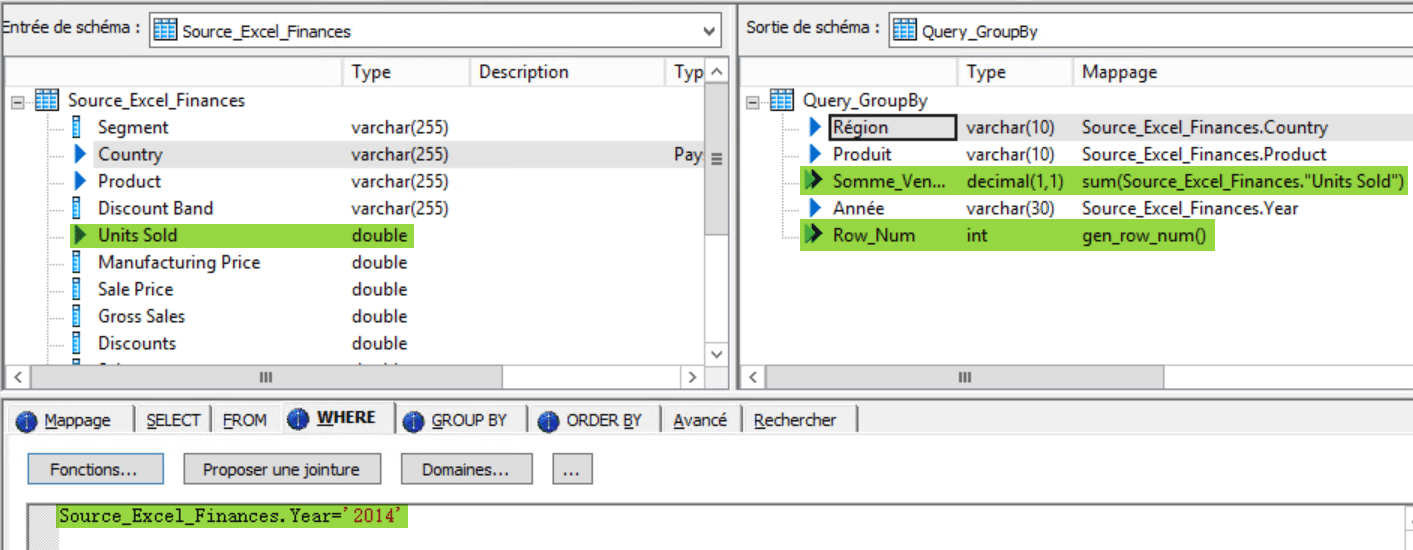
Le champs « Year » est filtré dès ce composant sur la valeur « 2014 » pour alimenter la sortie « Année » qui sera utilisée seulement pour paramétrer l’entête de sortie. Nous utilisons ici une fonction qui est une version simplifiée de gen_row_num_by_group(), la foncton gen_row_num() décrite dans ce tutoriel pour numéroter les lignes ce qui permettra de garder une unique ligne d’entête.
Nous réalisons ensuite toujours dans le même composant un GroupBy : cliquez déposez les champs à grouper dans la zone GroupBy, les valeurs identiques de ces champs seront regroupées lors du mappage :

Le GroupBy réalisé va vous permettre d’exprimer le champs de sortie Somme_Vente comme la somme des ventes pour une région donnée et un produit donné sur l’année filtré (2014 donc) :
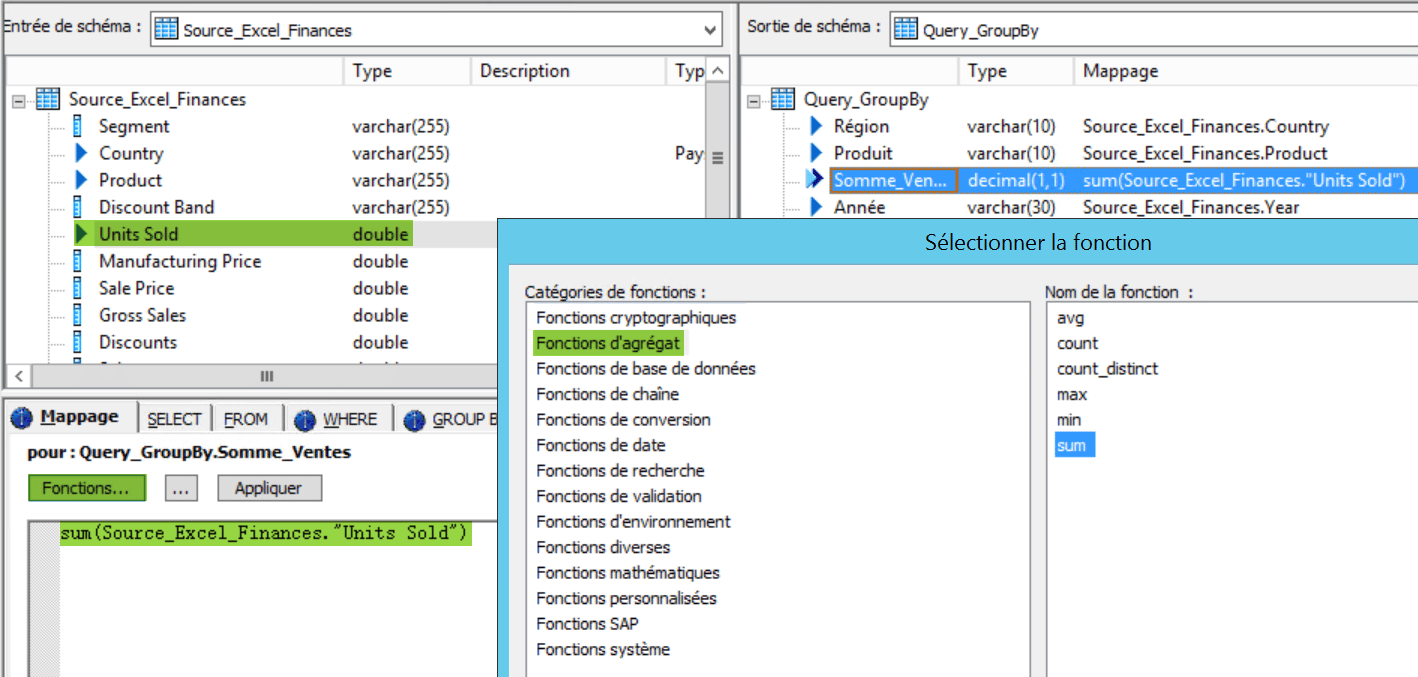
Cette somme nécessitant d’avoir mis en place l’agrégation réalisée par notre GroupBy, vous trouverez la fonction nécessaire dans la catégorie de fonctions « Fonctions d’agrégat ». D’autres fonctions sont disponibles dans cette catégorie vous permettant de compter les valeurs (distinctes ou non), d’extraire une moyenne, un maximum ou minimum.
La sortie Somme_Vente a été converti de manière forcée depuis un type double vers un type décimal pour pouvoir choisir un seul chiffre après la virgule. En cas de conversion de ce type si vous n’obtenez pas ce que vous désirez en sortie pensez à vérifier les avertissements lors de l’exécution pour vérifier comment ont été gérées les conversions forcée :
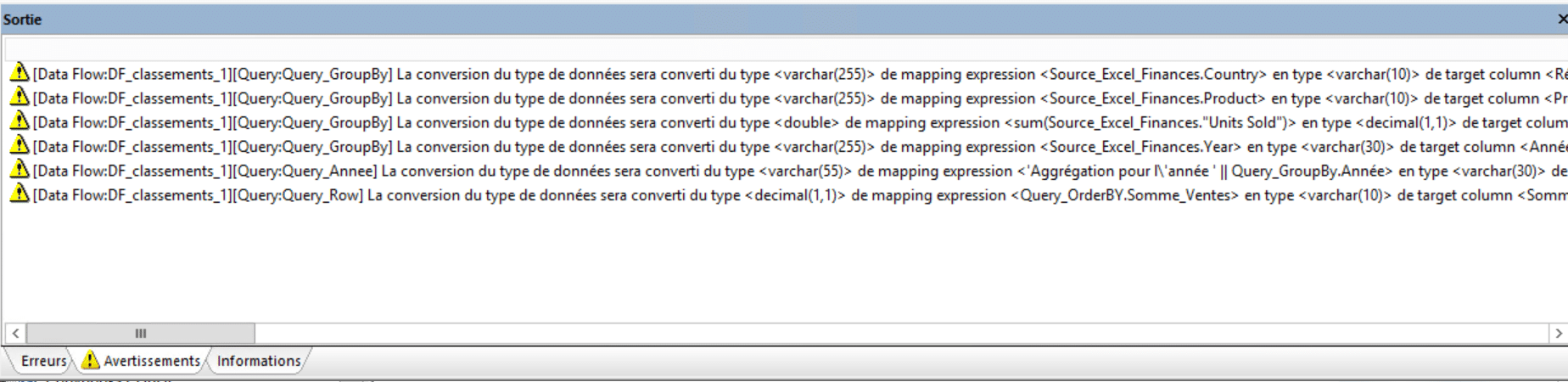
Vous pouvez en cas de problème utiliser des fonctions de la catégorie « conversion » pour régler vos conversions en finesse (lien à venir).
Composant Query_Année :
Avant de détailler les composant Query_GroupBy et Query_Row qui montrerons comment est employée la fonction gen_row_num_by_group(), vous allez voir la génération d’une entête paramétrée par l’année dans le composant Query_Année :
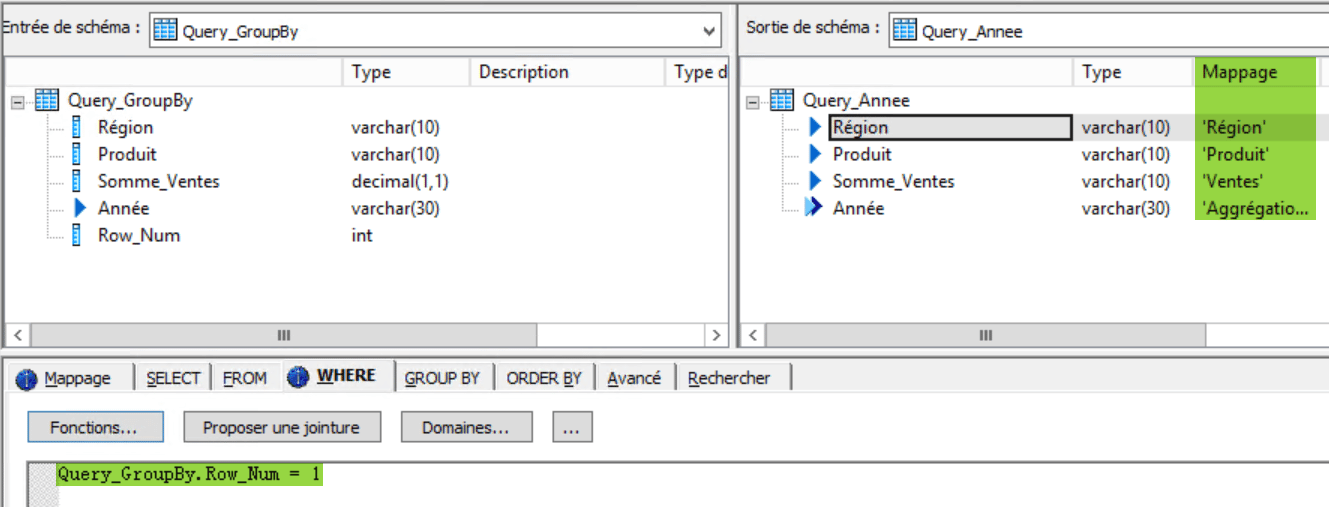
Le champs d’entrée Row_Num est filtré pour une valeur de 1 de manière à n’obtenir qu’une seule ligne d’entête. Les trois premiers champs d’entête « Région », « Produit » et « Somme_Ventes » n’étant pas paramétrés il ne sont pas mappés à l’entrée et contiennent directement leur valeur.
Par contre le champs « Année » est une chaîne de caractère paramétrée par l’année sur laquelle se fait l’agrégation avec utilisation d’une concaténation (opérateur ||) comme vous pouvez le voir ci – dessous :
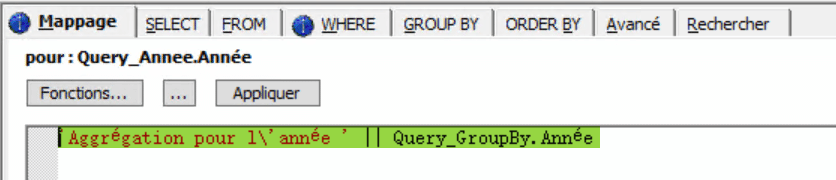
Nous verrons à la fin comment notre ligne d’entête est ajoutée grâce au composant Merge.
Composant Query_GroupBy :
Avant de numéroter nos groupes de valeur grâce à gen_row_num_by_group il est essentiel d’ordonner nos lignes selon la somme agrégée des ventes, nous allons aussi ordonner selon les région pour qu’elles apparaissent par ordre alphabétique. Utilisez le cliquez – déposer comme précédemment pour le GroupBy :
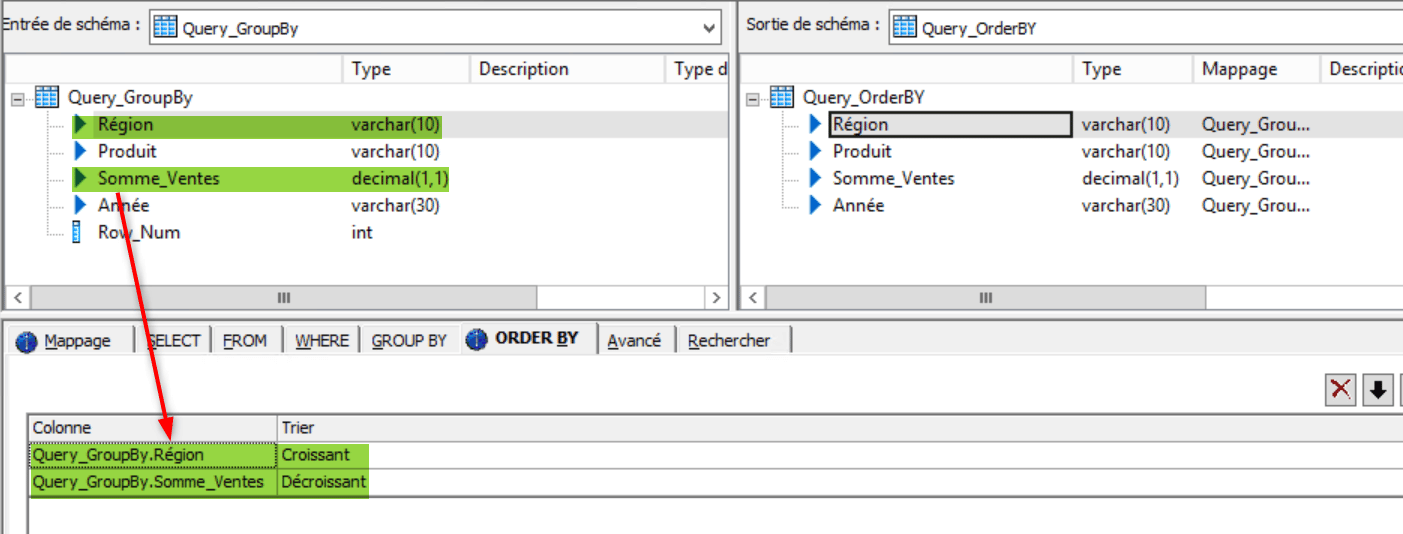
Nous ne mappons pas le champs d’entrée « Row_Num » qui servait seulement à la construction de l’entête.
Composant Query_Row :
Vous allez utiliser dans ce composant la fonction centrale de ce Dataflow : gen_row_num_by_group(champs) permet de numéroter toutes les lignes présentes pour chacune des valeurs de « champs » passé en paramètre, ce numéro est mappé dans la sortie Row_Num :
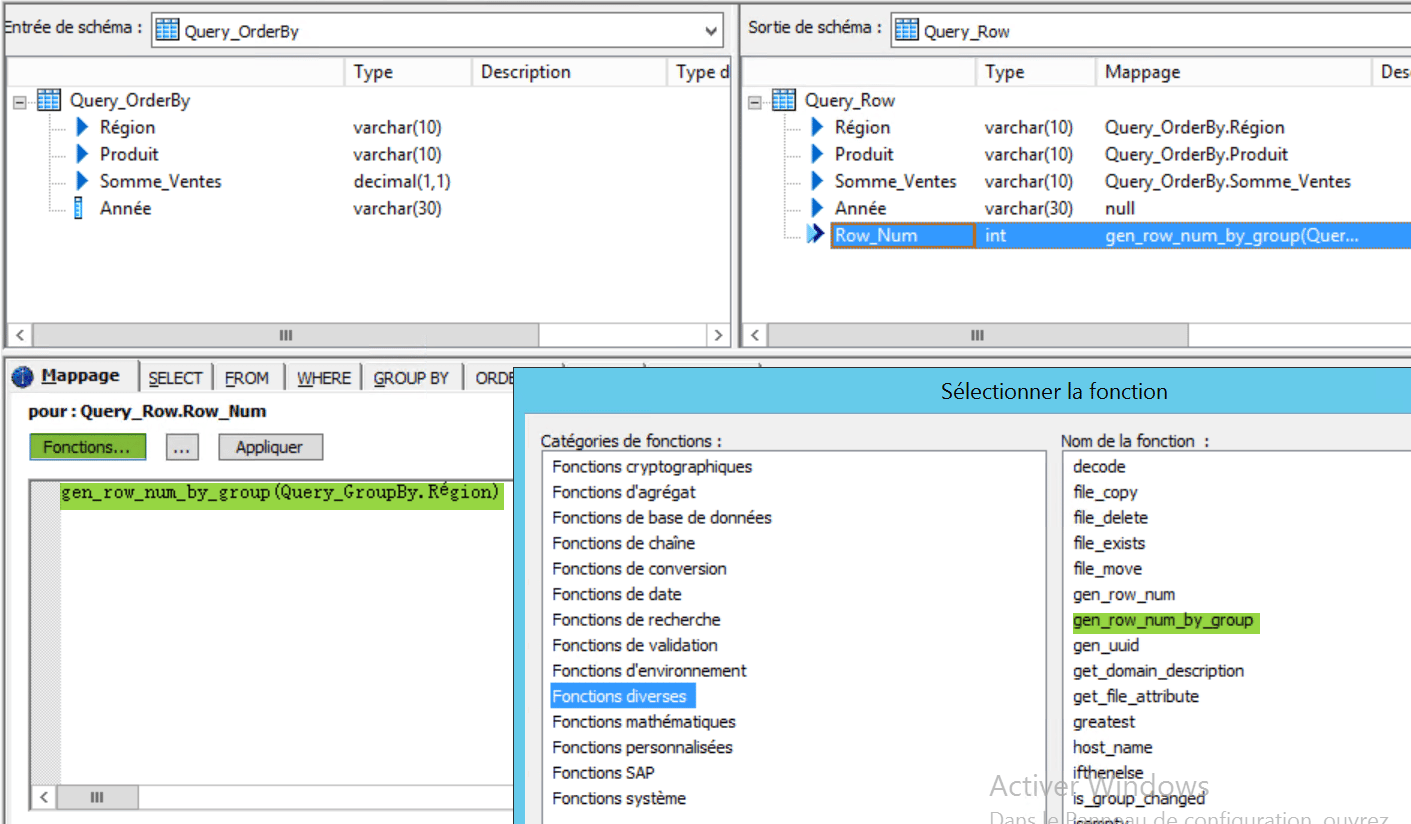
Les valeurs de Somme_Ventes vont donc être numérotées par Row_Num dans leur ordre d’apparition qui est l’ordre décroissant grâce au composant OrderBy qui précède.
Composant Query_Where :
Il ne reste plus qu’à filtrer les trois meilleures valeurs de Row_Num pour ne garder, pour chaque région, que les trois meilleurs produits selon le chiffre de vente sur l’année :

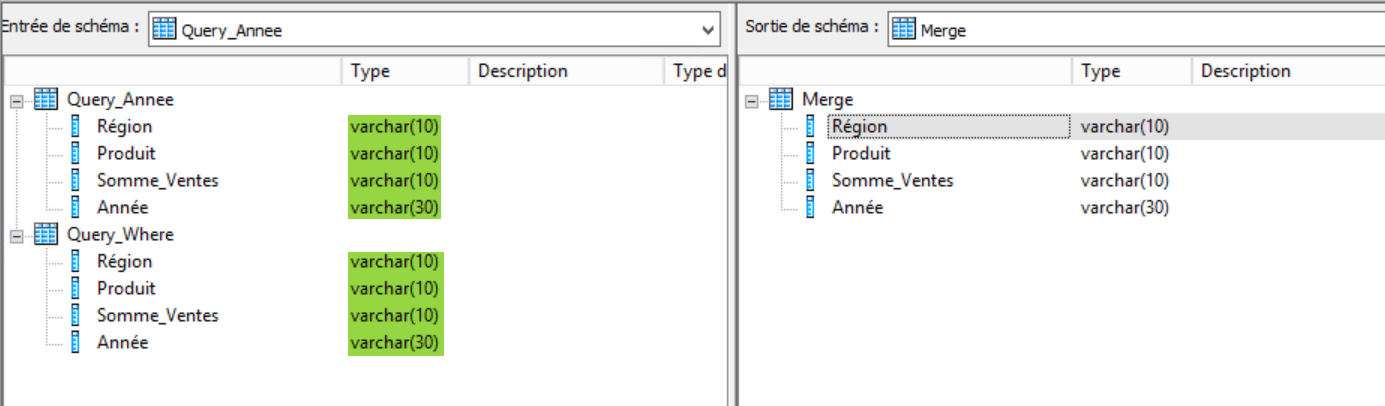
Composant Merge :
Ce composant permet de regrouper l’ensemble des lignes structurées précédemment avec l’entête que vous aviez généré, avant d’alimenter la cible avec le résultat obtenu . Vérifiez bien que les champs présent dans chacun des flux regroupés par Merge sont identiques en nom et en valeur, sinon votre JOB ne passera pas la validation. En effet il s’agit de créer une structure à partir de deux plus petites structures qui doivent donc être identiques :
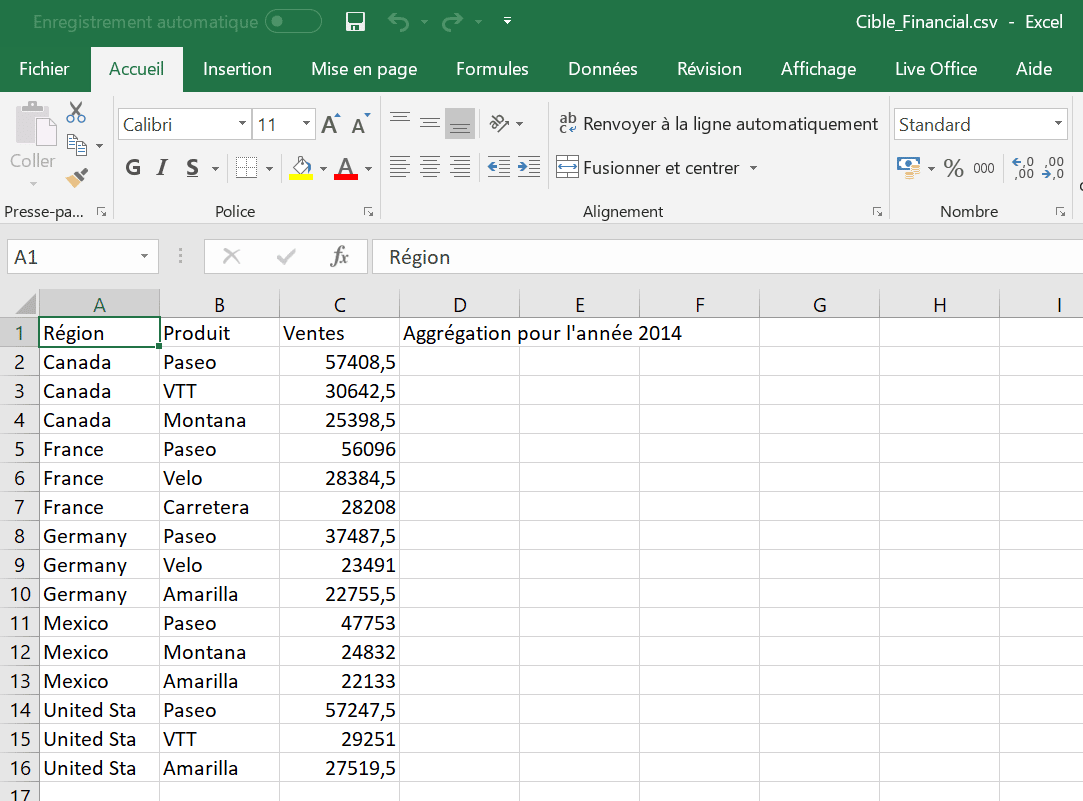
Résultat :
Vous obtenez bien, pour chaque région et agrégé sur l’année 2014, le classement des trois produits les mieux vendus, avec une entête paramétrée par l’année :
Vous savez désormais comment utiliser la fonction gen_row_num_by_group(champs) en association avec GroupBy et OrdeBy pour structurer vos données.

Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !