
Indexation de texte grâce aux fonctions word() de SAP Data Integrator
Dans ce tutoriel vous apprendrez comment utiliser les fonctions word() et word_ext() afin de segmenter et indexer les mots et phrases d’un texte.
Prérequis :
- Versions SAP Data Services (SAP BODS) 4.2
- Avoir installé SAP BODS avec un IPS (Platform Information Service) de version compatible.
- Avoir crée une base de donnée et configuré un référentiel local SAP BODS sur cette base. Disposer des droits d’accès à ce référentiel, définis depuis la CMC de l’IPS.
- Avoir lu le tutoriel créer un Job SAP BODS simple.
- Avoir lu le tutoriel d’introduction aux fonctionnalités du transformateur Query.
Contexte :
Nous utilisons un Dataflow capable d’extraire les informations d’un texte comme le suivant, quel que soit sa structure de paragraphes. A la sortie de ce traitement chaque mot est indexé par sa position dans la ligne, la position de cette ligne relativement au début du paragraphe, le numéro de son paragraphe et la position de la ligne depuis le début du fichier, et les phrases sont découpées :
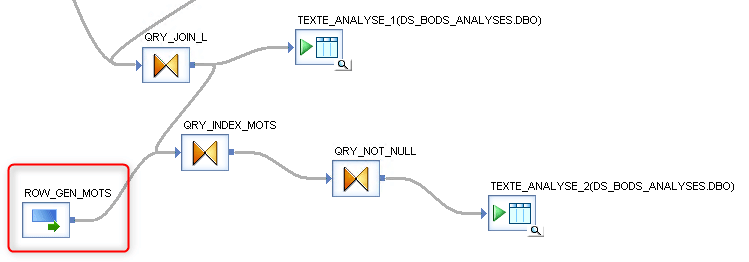
Ce Dataflow est le suivant. Nous allons uniquement nous intéresser dans ce tutoriel au traitement encadré en rouge, commençant à partir du schéma de sortie du Query QRY_JOIN_L. L’entrée de notre traitement est donc visible dans la table cible TEXTE_ANALYSE_1.

En visualisant le contenu de TEXTE_ANALYSE_1 on peut voir que le contenu du texte source a déjà été indexé selon la position de la ligne depuis le début du fichier (INDEX_ABS_LIGNE), le numéro de son paragraphe (INDEX_PARAG) et la position la ligne relativement au début du paragraphe (INDEX_REL_LIGNE) :

Il reste donc à indexer la position de chaque mot depuis le début de la ligne puis à découper les phrases.
Solution :
Nous allons utiliser des fonctions capables de découper une chaîne de caractère (notre ligne en entrée) en une suite de chaînes (des mots) selon un caractère séparateur donné. Comme nous ne savons pas le nombre de mots contenus dans chaque ligne nous devons tout d’abord définir une variable globale ($VAR_G_NB_MAX_MOTS) fixant une borne supérieure à ce nombre. Ci dessous nous avons fixé cette limite à 30 mots par ligne :

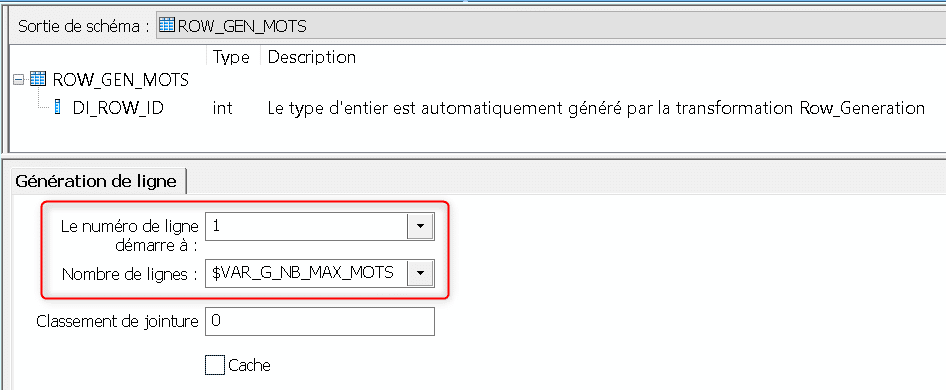
Le composant générateur ROW_GEN_MOTS va être utilisé en produit cartésien avec nos lignes d’entrée dans le Query QRY_INDEX_MOTS afin de générer pour chacune des lignes d’entrée un nombre de ligne égal à $VAR_G_NB_MAX_MOTS :
Au sein de ROW_GEN_MOT l’indexation de ces mots entre 1 et $VAR_G_NB_MAX_MOTS est générée :
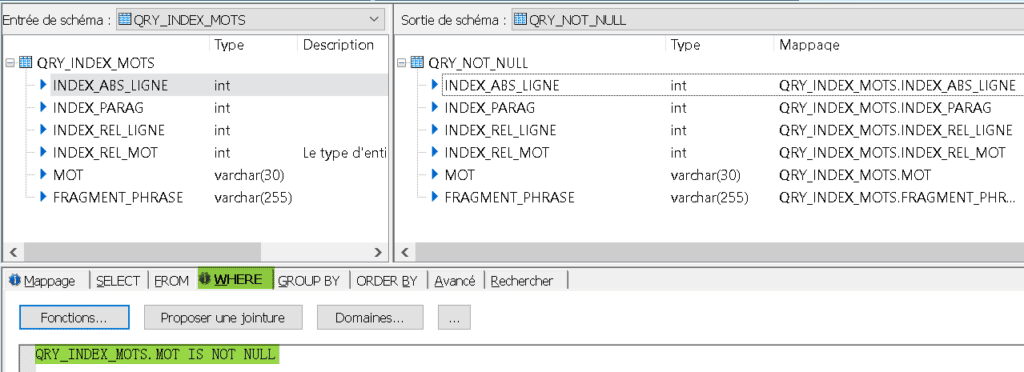
Ensuite au sein de QRY_INDEX_MOTS un champs de sortie « MOT » est ajouté qui pour la nième ligne issue de ROW_GEN_MOTS générera le mot d’index n. A cette fin la fonction word() est utilisée, celle – ci prend en premier argument la chaîne de caractère à découper et en deuxième argument le numéro d’élément extrait. Avec la fonction word() le séparateur d’élément est » » donc les éléments obtenus seront bien les mots :

Remarque : si le numéro d’index proposé par ROW_GEN_MOTS est supérieur au nombre de mots dans la phrase la fonction word() renvoie NULL.
Nous voulons aussi obtenir pour chaque ligne d’entrée le premier fragment de phrase rencontré. A cette fin nous utilisons la fonction word_ext() qui dispose, en plus des deux arguments de word(), d’un troisième argument indiquant le séparateur d’éléments. Nous voulons extraire une phrase donc nous allons utiliser le séparateur « . » :

Le transformateur Query QRY_NOT_NULL est ensuite chargée de nettoyer la liste de mots obtenus de toutes les positions de mots en trop, pour lesquelles NULL avait été renvoyé par word() :
On peut vérifier en sortie qu’on obtient bien pour chacune des lignes la liste ordonnée des mots utilisés et le début de phrase :

Remarque : Vous pouvez faire de même avec les phrases de chaque lignes que ce qui a été réalisé ici pour les mots : créer un variable globale indiquant le nombre maximal de phrases par ligne (ou fragments de phrase pour les débuts et fin de ligne) puis indexer ces phrases selon leur numéro dans la ligne. Les phrases à cheval sur plusieurs lignes peuvent alors être récupérées par une simple jointure grâce à la structure générée en amont dans le traitement.
Vous savez désormais comment utiliser les fonctions word() et word_ext() afin de segmenter et indexer les mots et phrases d’un texte.

Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !