
Utilisation de Talend Data Mapper pour les hiérarchies avec boucles imbriquées
Dans ce tutoriel vous apprenez comment créer une MAP depuis le Data Mapper ou Hierarchical Mapper afin de traiter des données structurées hiérarchiquement selon des boucles imbriquées.
Prérequis :
- Avoir installé Studio Talend, la partie intégration ETL (Extract Transform Load) des solutions Talend.
- Version : Talend 8.0
- Si connecté au Cloud Talend depuis le Studio Talend, il faut que l’utilisateur soit muni d’un rôle « Integration Developer » avec ses autorisations par défaut.
- Avoir installé la fonctionnalité « Talend Data Mapper » depuis le gestionnaire de fonctionnalités du Studio Talend.
- Avoir étudié le tutoriel suivant : Traiter des données XML avec une boucle.
- Avoir étudié le tutoriel suivant : Utilisation du Data Mapper dans un Job d’intégration.
Contexte :
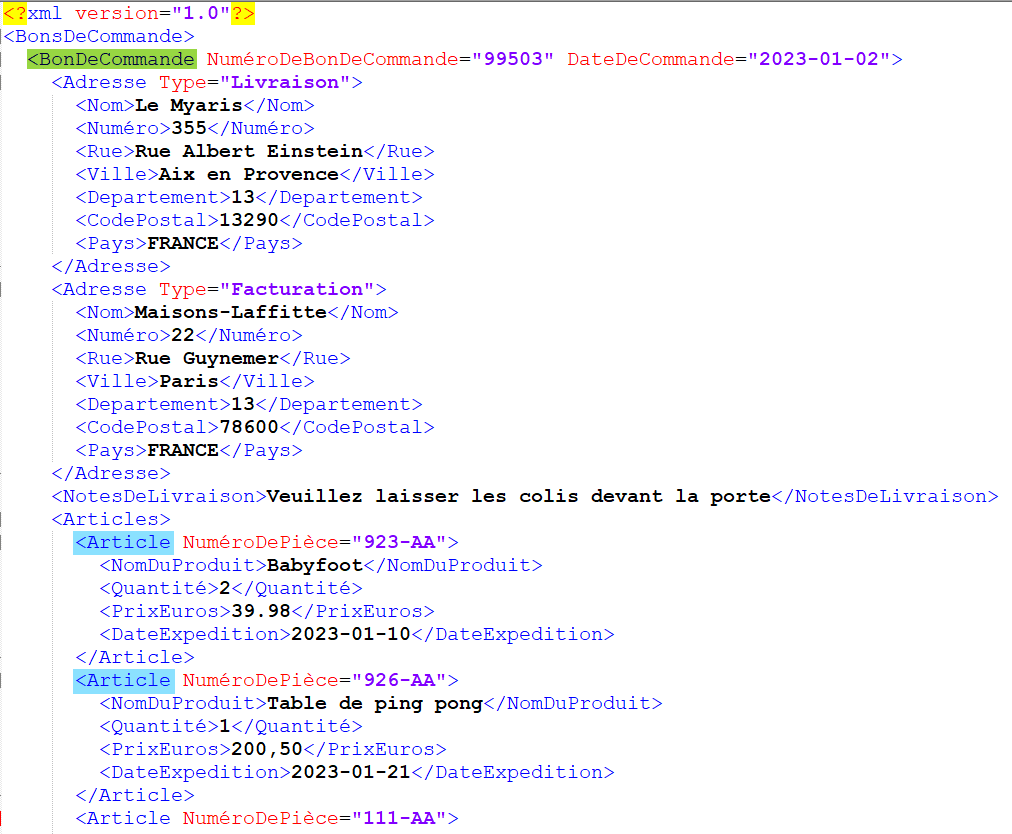
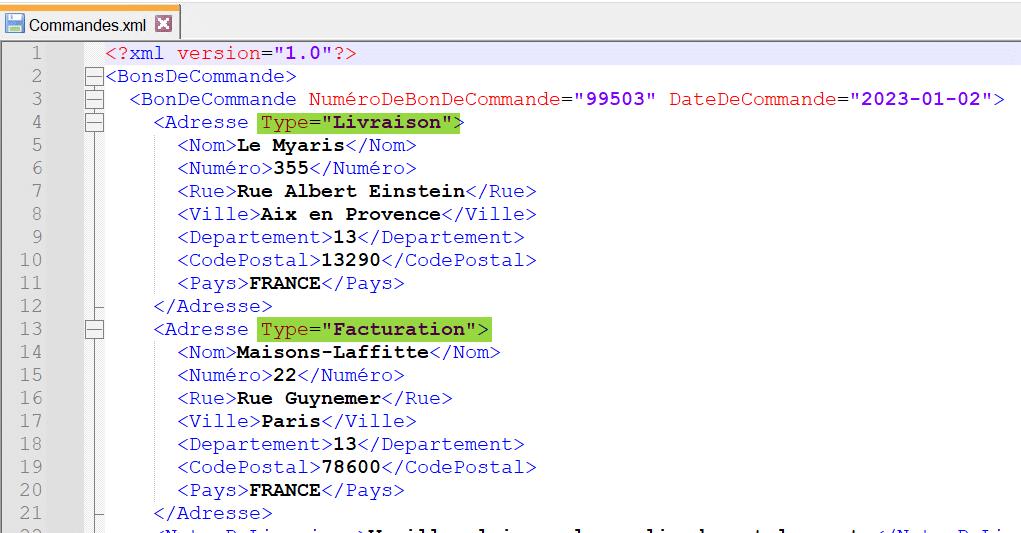
Nous disposons du fichier XML suivant décrivant des bons de commandes contenant chacun divers articles commandés selon diverses quantités. Il s’agit d’une structure XML avec boucles imbriquées, en effet les boucles sont présentes à deux niveaux : la balise « BonDeCommande » et la balise « Article » à l’intérieur de la première. Il existe aussi une boucle sur la balise « Adresse » imbriquée dans celle du bon de commande :
Talend Studio dispose par défaut du composant tMapXML afin de mapper les structures XML. Ce composant permet d’importer une structure XML depuis un fichier template puis de mapper ses éléments vers une nouvelle structure hiérarchique ou bien vers une structure plate (fichier CSV, table de base de données).

Ce composant tMapXML permet de mapper des structures XML mais avec certaines limites aussi présentes sur le composant tWriteXMLField.. En effet si une boucle est présente sur un élément comme ci – dessous sur « BonDeCommande » et qu’on essaie de créer une boucle sur un élément parent ou enfant (Article) de cet élément on rencontre un blocage :
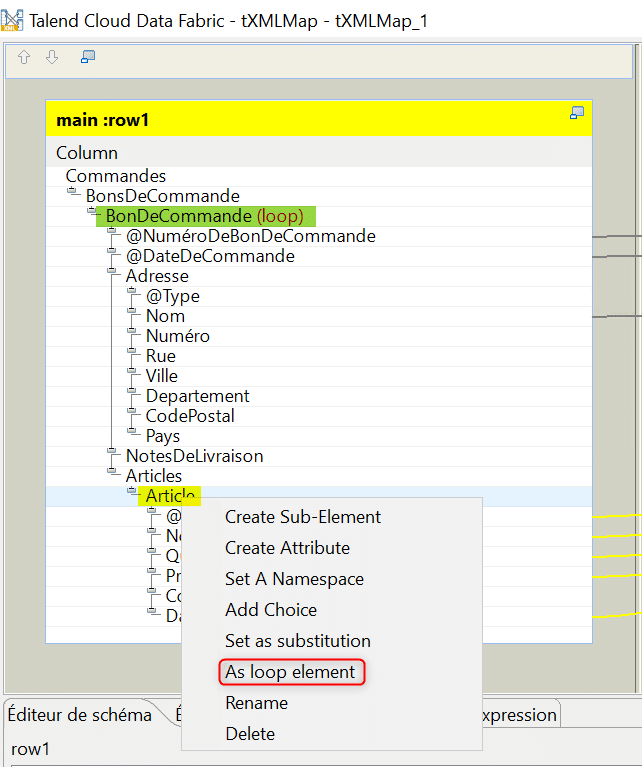
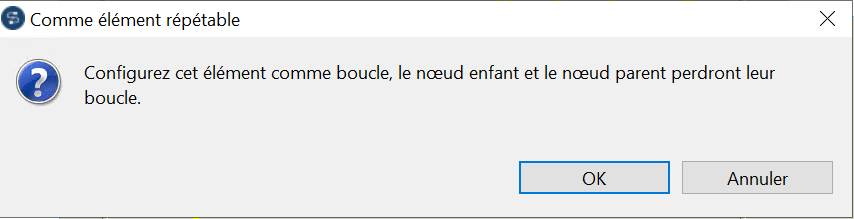
Le processus de création d’une boucle sur un élément impose en effet que la boucle présente sur un de ses éléments parent ou enfant est supprimée :
Cette limitation existe aussi pour le traitement des données au format JSON avec le composant tWriteJSONField.
Solution :
Afin de contourner cette limitation il est possible d’utiliser le Data Mapper de Talend qui permet de mapper des données hiérarchiques (XML, JSON) avec boucles imbriquées.
Dans un premier temps nous créons les structures d’entrées et de sortie (1) puis nous allons créer le mapping entre ces structures (2). Ce mapping pourra ensuite être glissé – déposé en tant que composant de mapping dans notre Job Talend.
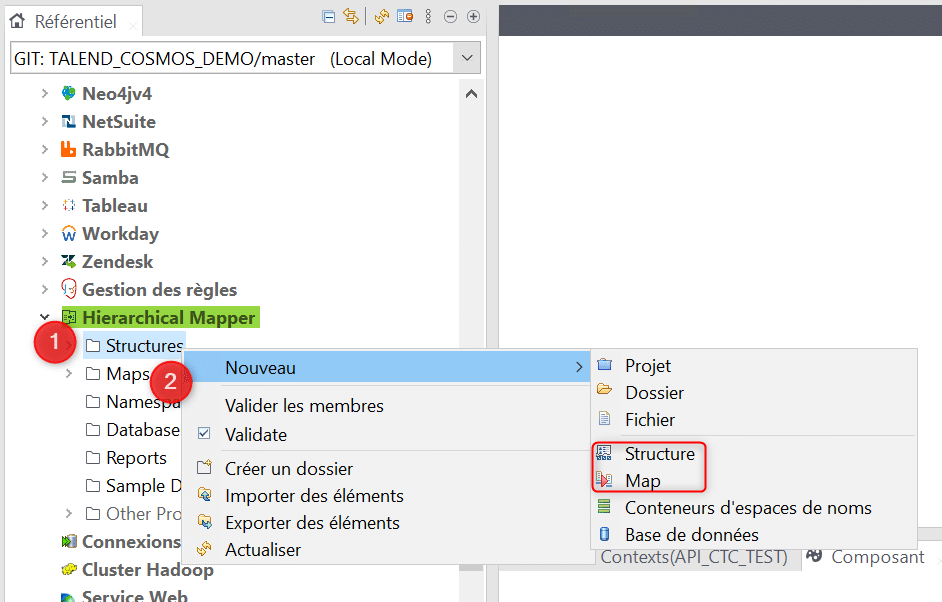
La structure d’entrée est créée à partir d’un fichier exemple :
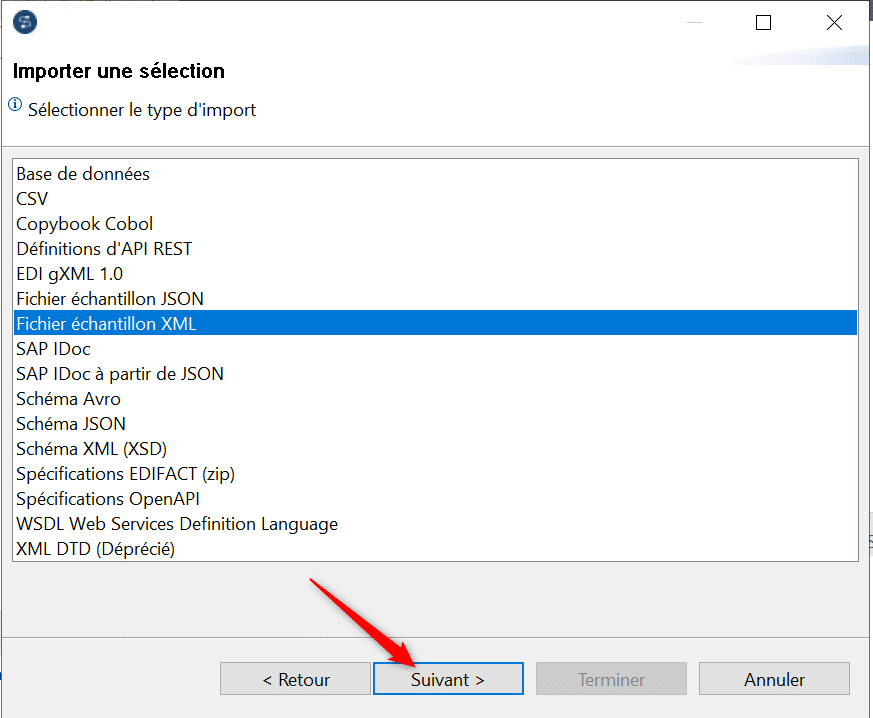
Le fichier importé est « Commandes.xml » :
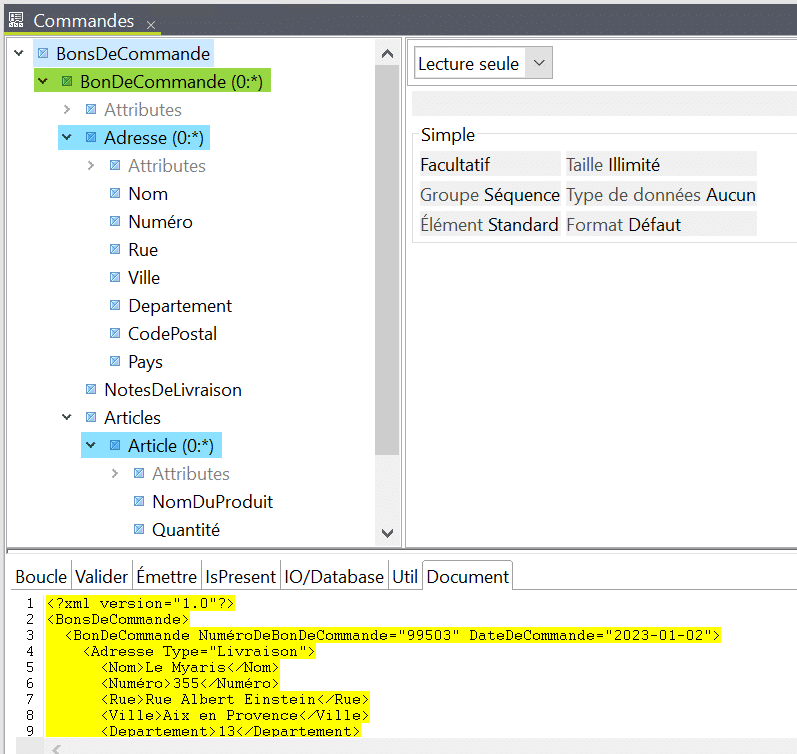
La structure a été générée et montre deux boucles imbriquées :
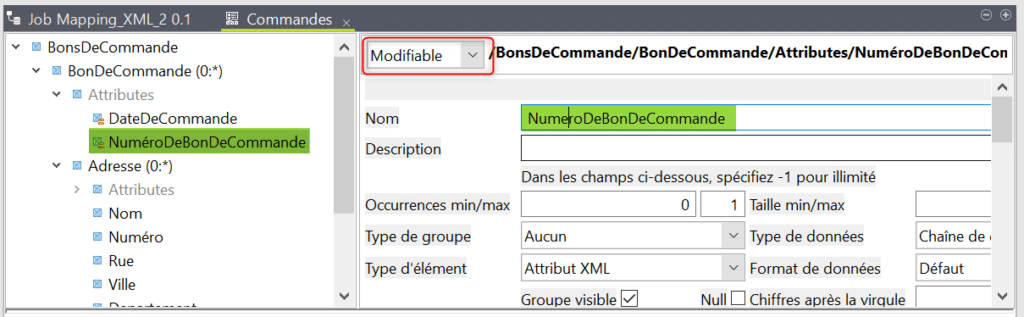
Afin de modifier un élément de la structure cliquez dessus puis sélectionnez « Modifiable« . Il est recommandé de supprimer les accents car ceux – ci peuvent être mal lus par la suite :
Pour la cible nous importons une structure plate depuis un fichier template CSV :
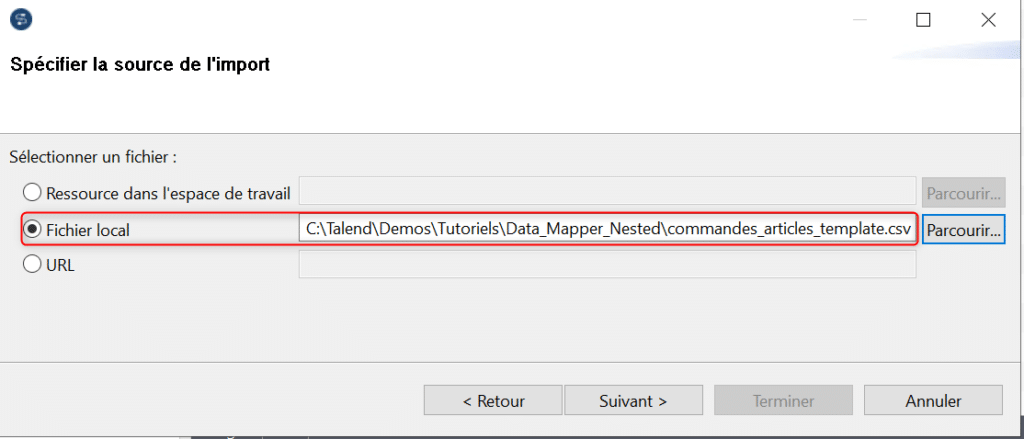
Indiquez le délimiteur et l’encodage et cochez « Ignorer la lecture de l’entête » pour spécifier que la première ligne ne contient pas de données mais les noms des champs :
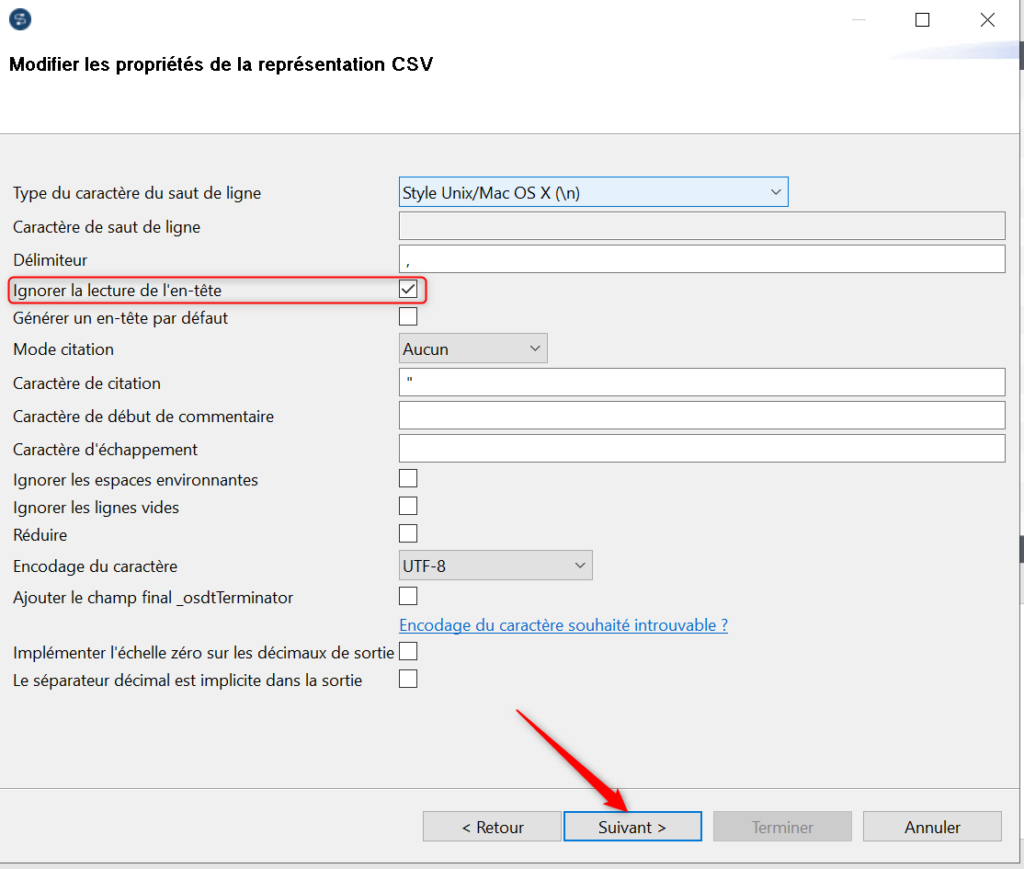
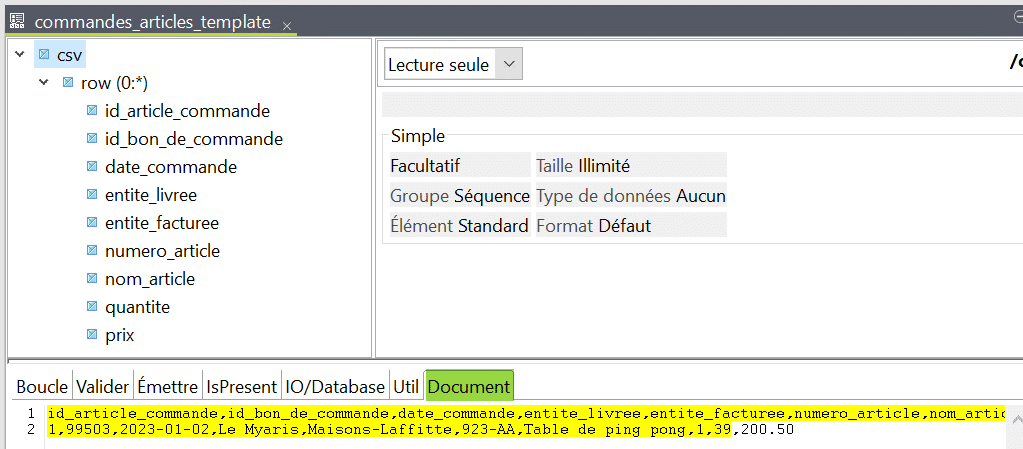
La structure cible plate est générée à partir du fichier CSV exemple, avec les noms de colonne récupérés à partir de l’entête du fichier :
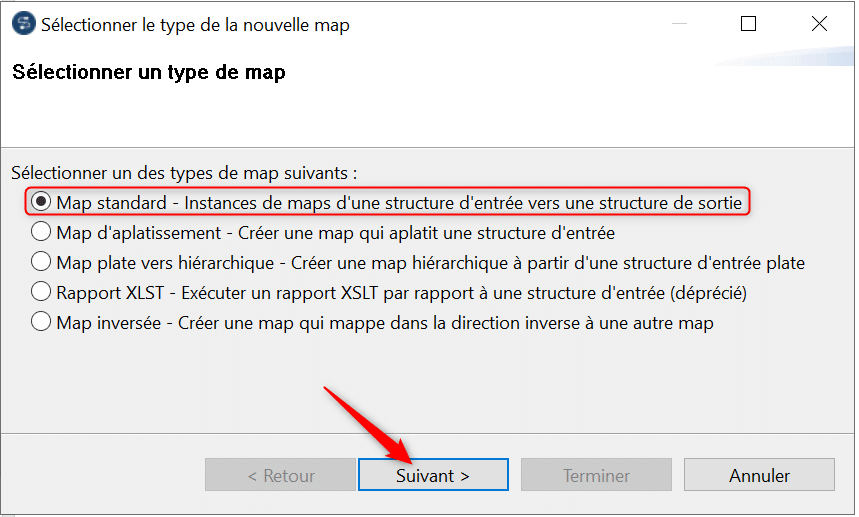
Créez maintenant une Map standard qui va permettre de construire le mapping entre des structures d’entrée et de sortie existantes :
Indiquez le nom de la Map et son dossier puis cliquez sur « Terminer » :
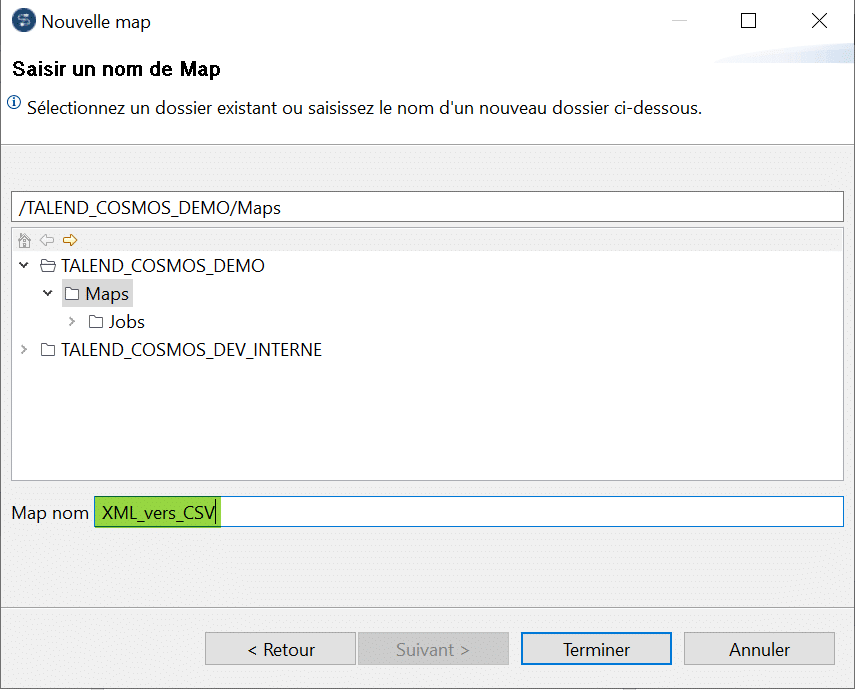
La Map a été créée à vide. Vous pouvez maintenant y cliquer – déposer sa structure source et sa structure cible :
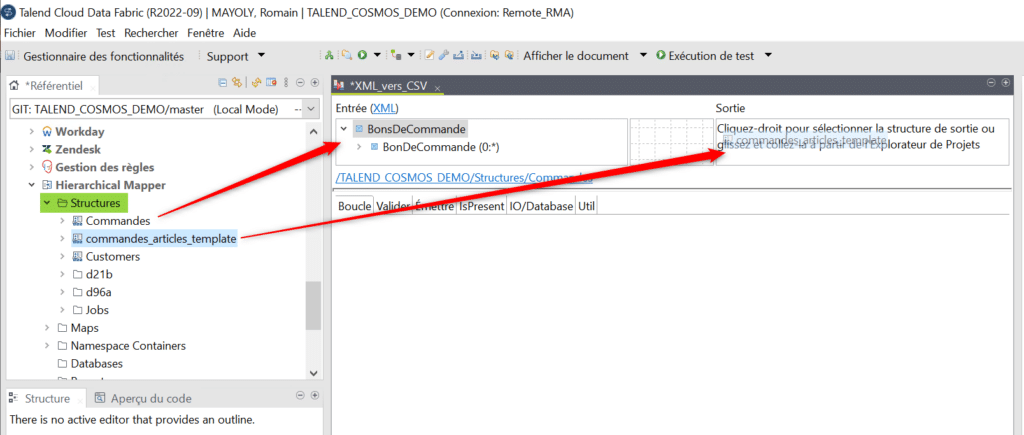
Déroulez les structures sources et cibles puis cliquez sur chaque élément source à mapper vers la cible et déposez le sur son élément cible :
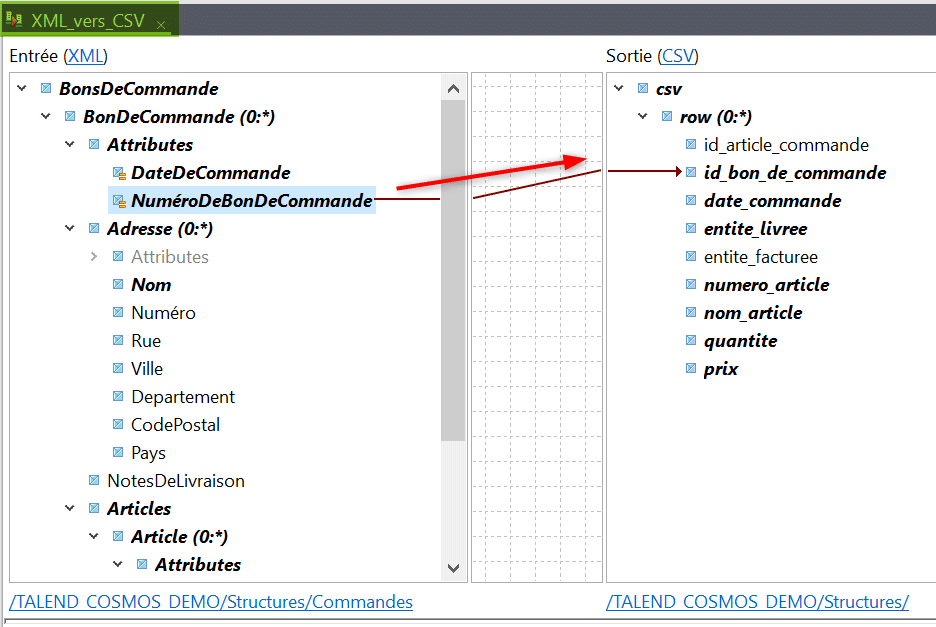
Une fois le mapping réalisé lorsque vous cliquez sur chacun des éléments de la structure hiérarchique d’entrée l’ensemble des éléments cibles que ses sous – éléments mappent est indiqué. La structure en double boucle imbriquées sera automatiquement comprise et ainsi dans les données de sortie pour chaque bon de commande il y aura plusieurs lignes chacune contenant un article du bon de commande :
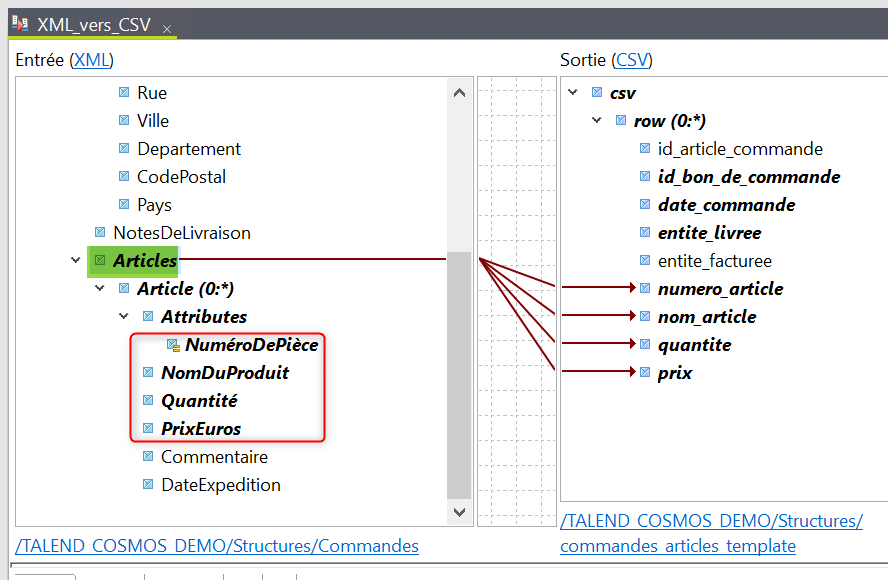
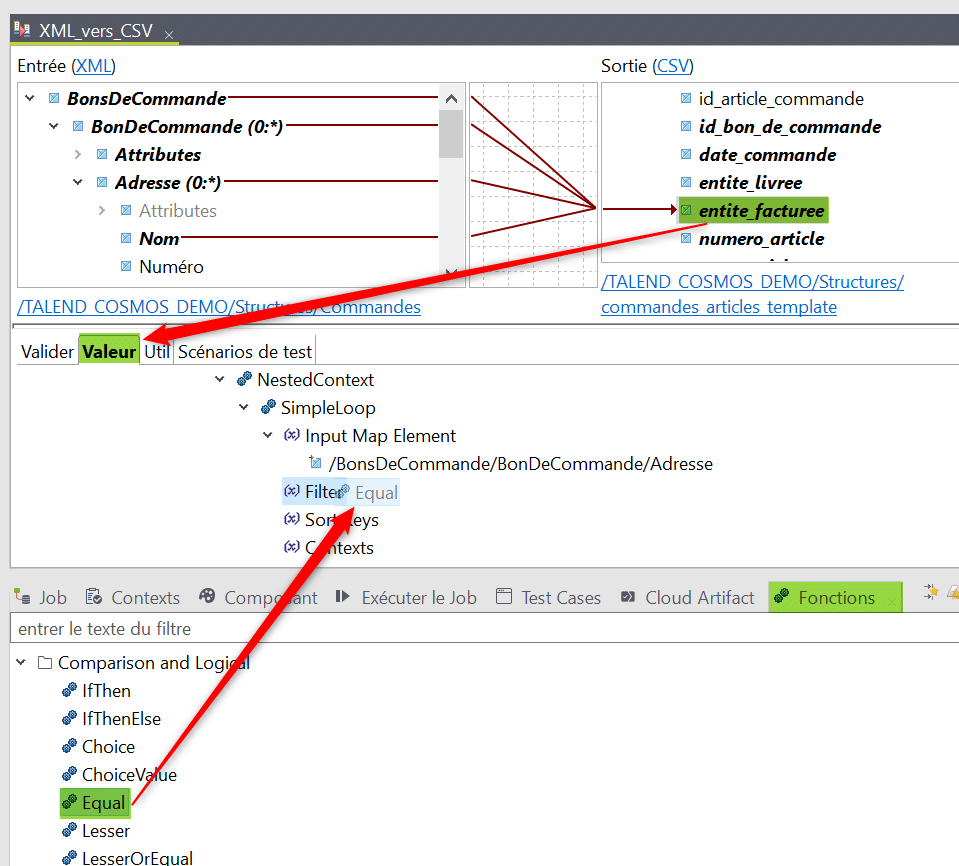
Un cas particulier est celui des adresses, il s’agit d’une boucle imbriquée dans celle des bons de commande mais pour chaque cas elle ne contient que deux entrées correspondant respectivement à l’entité livrant les articles et celle les recevant. Ainsi les champs de sortie « entite_livree » et « entite_facturee » sont toutes deux mappées au même champs d’entrée « Nom » de la balise d’adresse :
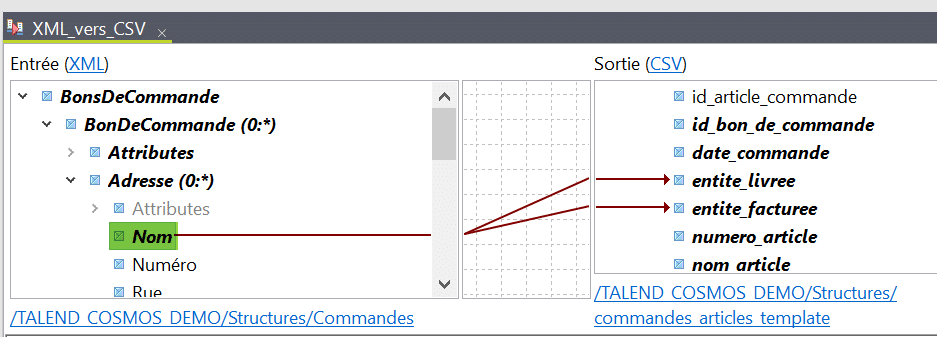
Afin de distinguer ces deux champs de sortie nous allons devoir utiliser dans leur mapping un filtre sur la valeur de l’attribut « Type » de la balise « Adresse » :
Vous allez devoir utiliser des fonctions afin de paramétrer ce filtre. Par défaut l’onglet des fonctions n’est pas affiché. Pour l’ajouter allez dans « Fenêtre » puis « Montrer la vue » :
Faites une recherche de la vue « Fonctions » puis ajoutez là :
Cliquez sur le champs cible « entite_facturee » puis ouvrez l’onglet des fonctions. Cliquez – déposez la fonction « Equal » dans la section « Filter » du champs entite_facturee :
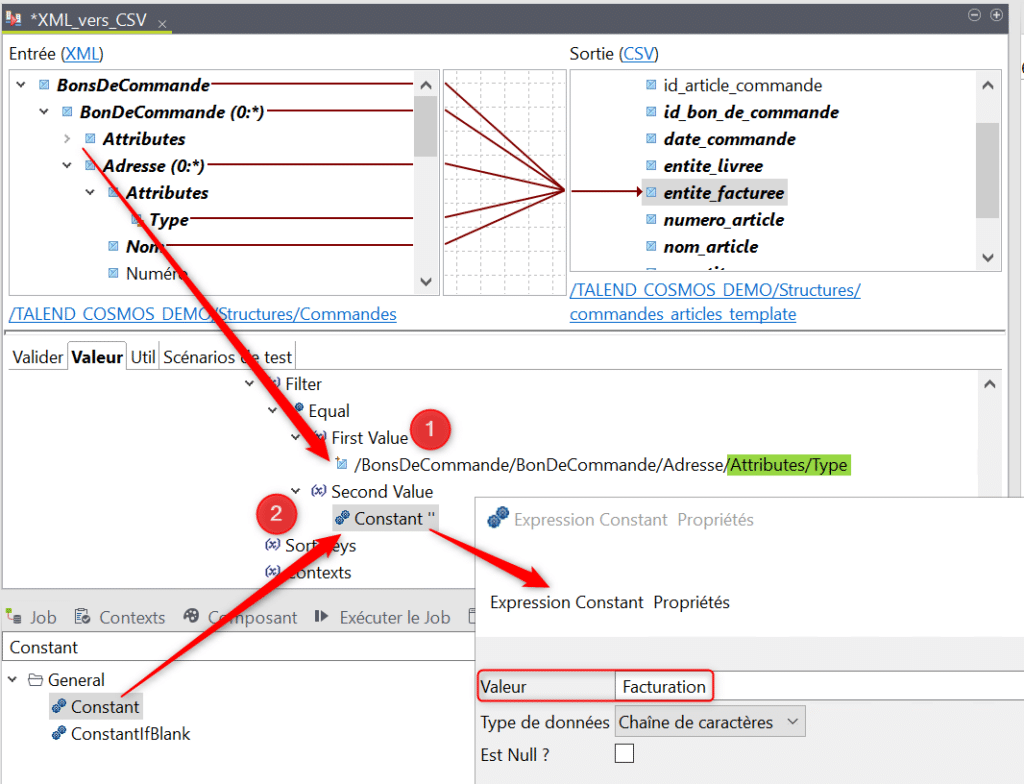
Deux sous sections « First Value » et « Second Value » de la fonction « Equal » sont apparues. Cliquez – déposez l’attribut « Type » de « Adresse » dans la première sous section (1) puis cliquez – déposez la fonction « Constant » dans la deuxième sous section (2). Double cliquez ensuite sur Constant et indiquez la valeur « Facturation » :
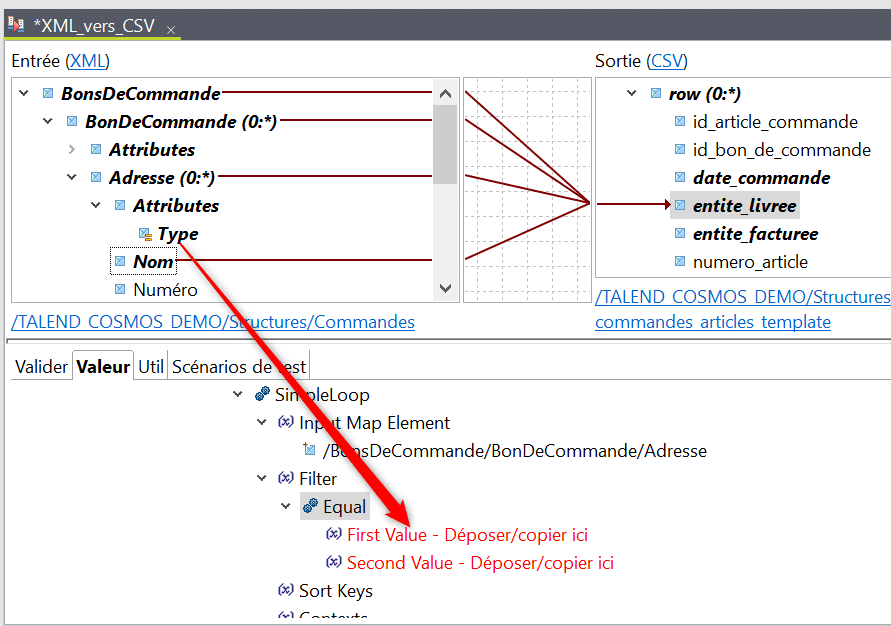
Procédez ensuite de même avec le champs « entite_livree« , cette fois – ci en indiquant la valeur « Livraison » dans le filtre puis sauvegardez.
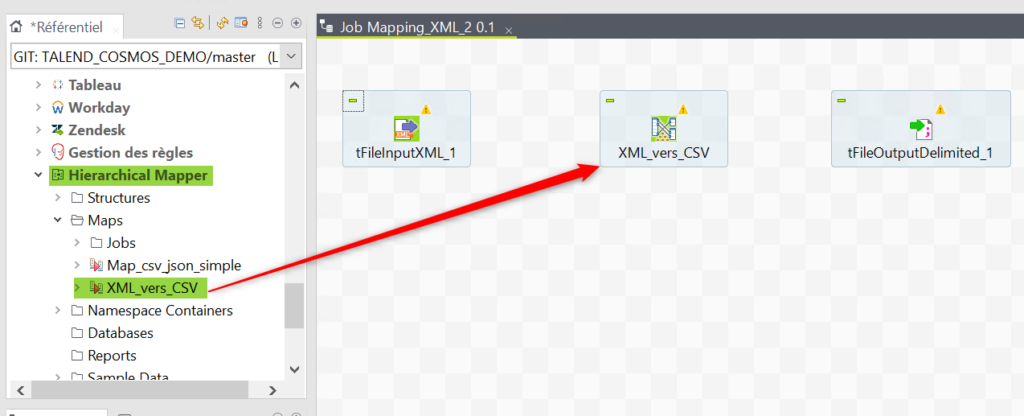
Créez un Job Talend et insérez – y les composants tFileInputXML et tFileOutputDelimited. Ils vont respectivement permettre la lecture du fichier XML et l’écriture des données cibles obtenues dans un fichier CSV. Ouvrez le Hierarchical Mapper puis cliquez – déposez la Map précédente vers votre Job :
Vous savez désormais comment créer une MAP depuis le Data Mapper afin de traiter des données structurées hiérarchiquement selon des boucles imbriquées.
Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !