
Migration d’Azure Data Factory (ADF) vers Data Factory dans Microsoft Fabric
Temps de lecture : 2 minutes
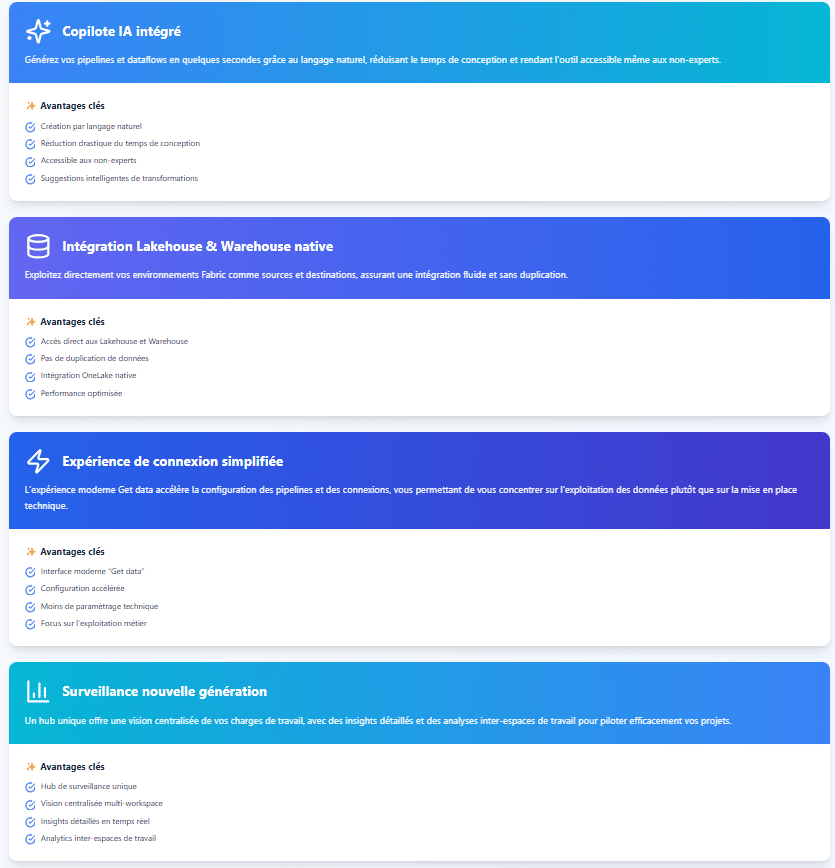
Ce qui rend Fabric Data Factory spécial
Data Factory dans Microsoft Fabric n’est pas seulement une mise à niveau : il s’agit d’une nouvelle façon de réfléchir à l’intégration des données. Voici quelques-unes des caractéristiques marquantes qui font de Fabric Data Factory un élément révolutionnaire :
| Élément ADF/Synapse | Équivalent dans Fabric Data Factory | Points clés |
| Pipelines et Dataflows | Pipelines Fabric et Dataflow Gen2 (Power Query en ligne) | Les pipelines et dataflows ADF sont recréés dans Fabric à l’aide des Dataflows Gen2 (basés sur Power Query) ou des Pipelines Fabric, pour gérer l’ingestion, la transformation et l’orchestration des données. |
| Linked Services / Datasets | Connections + configurations in-line | Les Linked Services sont remplacés par des Connexions Fabric, qui définissent l’accès aux sources de données. Les Datasets deviennent des paramètres ou définitions de tables directement intégrés aux activités (plus de configuration “inline”). |
| Integration Runtimes (IR, SHIR) | Data Gateway Fabric (On-premises ou Virtual Network) | Les Integration Runtimes sont remplacés par la Data Gateway Fabric, qui assure la connectivité sécurisée entre les environnements locaux, les réseaux virtuels et le service Fabric. |
| Activités non supportées (U-SQL, MapReduce, etc.) | Activités natives Fabric (Notebook, Spark, Pipeline, etc.) | Les activités obsolètes ou non supportées doivent être réimplémentées à l’aide des outils modernes Fabric, tels que Notebooks Spark, Data Pipelines ou Dataflows Gen2. |
Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !