
Apache Spark dans Microsoft Fabric : l’essentiel
Microsoft Fabric intègre nativement Apache Spark, le moteur de traitement distribué de référence dans les environnements Big Data. Cette intégration managée permet aux data engineers et data scientists de préparer, transformer et enrichir les données directement dans le Lakehouse, sans déplacer les fichiers ni gérer d’infrastructure.

Fabric fournit des clusters Spark prêts à l’emploi pour analyser et traiter la grosse volumétrie de données, avec prise en charge de PySpark (Python), Spark SQL, Scala, Java et R, ainsi qu’un écosystème riche de bibliothèques (I/O, ML, streaming, etc.). Les tables créées dans le Lakehouse sont immédiatement exposées via le point de terminaison analytique SQL, ce qui unifie ingénierie et analyse au sein d’une même plateforme : le cœur du Lakehouse moderne.
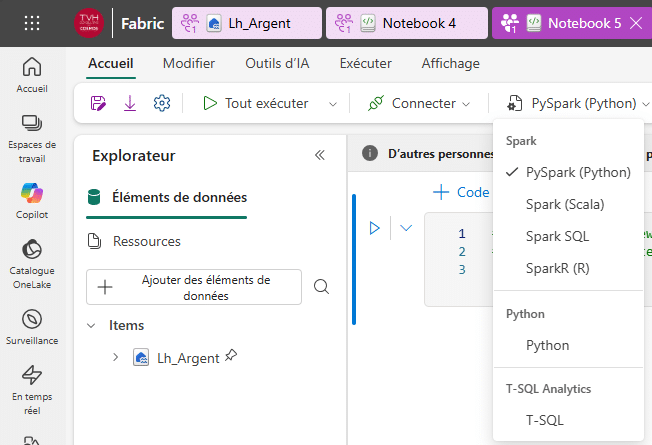
Pour passer de l’exploration à la production, Fabric propose deux modalités : Notebooks (interactifs) et Définition de travail Spark (planifiés et orchestrés).
| Besoin | Outil recommandé | Mode d’exécution | Cas d’usage typique |
| Exploration, test, data science | Notebook Spark | Interactif | Exploration, prototypage, validation |
| Ingestion et transformations lots | Définition de travail Spark | Automatisé / planifié | Traitements récurrents, workflows de production |
| Streaming / quasi temps réel | Définition de travail Spark | Continu (Structured Streaming) | Ingestion Kafka/Event Hubs, calculs en continu |
Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !