
Chargement d’une table à partir d’un fichier plat (délimité) – Partie 1
Dans ce tutoriel, découvrez comment concevoir un job de type batch permettant d’extraire des données à partir d’un fichier plat, les transformer puis les charger dans une table oracle.
Un fichier plat est un fichier texte. Il contient, généralement, un seul enregistrement par ligne. Il existe plusieurs conventions pour représenter les données. Les formats CSV, DSV par exemple permettent de séparer les champs à l’aide d’un séparateur comme la virgule ou la tabulation.
- Prérequis : Accès à une base de données de type Oracle ou autre, un fichier texte contenant les données brutes
- Version: SAP Data Services 4.2
- Application: Data Services Designer
1. Connexion au Designer
Data Services Designer fournit un environnement de développement d’interface utilisateur graphique dans lequel vous définissez une logique d’application de données pour extraire, transformer et charger des données de bases de données et d’applications dans un entrepôt de données utilisé pour les requêtes analytiques et à la demande. Vous pouvez également utiliser Designer pour définir des chemins logiques pour traiter des requêtes basées sur des messages et des transactions d’applications Web, front-office et back-office.
- Saisissez vos références utilisateur pour le CMS
- Système : Spécifiez le nom de serveur et, facultativement, le port du CMS.
- Nom d’utilisateur: Spécifiez le nom d’utilisateur à utiliser pour la connexion au CMS.
- Mot de passe: Spécifiez le mot de passe à utiliser pour la connexion au CMS
- Authentification: Spécifiez le type d’authentification utilisé par le CMS
- Cliquez sur Se connecter
Le logiciel tente de se connecter au CMS à l’aide des informations spécifiées. Lorsque vous êtes connecté, la liste des référentiels locaux disponibles s’affiche
- Sélectionnez le référentiel que vous souhaitez utiliser
- Pour vous connecter à l’aide du référentiel sélectionné, cliquez sur OK
Lorsque vous cliquez sur OK, vous devez saisir le mot de passe pour le référentiel Data Services. Ce comportement par défaut peut être modifié en ajoutant les droits nécessaires au référentiel dans le CMC. Pour en savoir plus, voir le Guide d’administration
 | 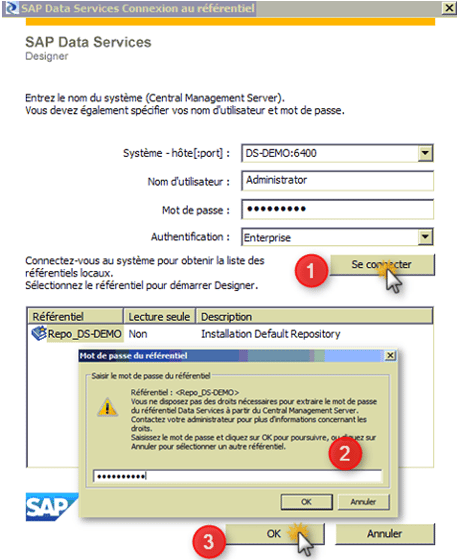 |
Le deuxième mot de passe de demandé est le mot de passe d’accès au référentiel. Afin de pouvoir modifier ce comportement par défaut, il faut donner les droits nécessaires à l’utilisateur au référentiel dans le CMC.
2. Création d’un Projet
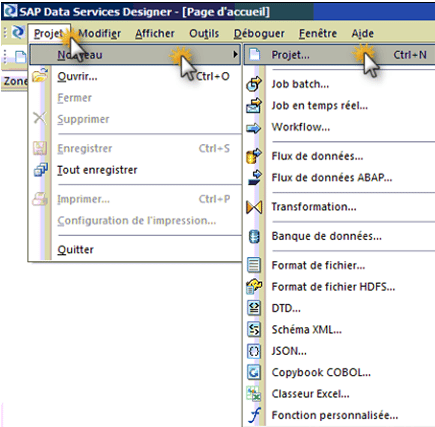
- Sélectionnez Projet–>Nouveau–>Projet.
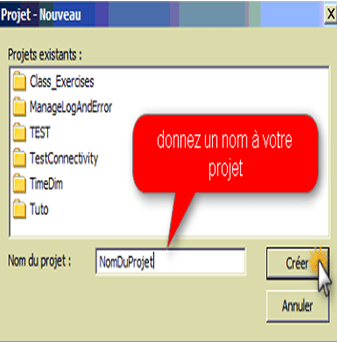
- Entrez le nom de votre nouveau projet.
Le nom peut comporter des caractères alphanumériques et des traits de soulignement (_). Il ne peut pas contenir d’espaces.
- Cliquez sur Créer
 |  |
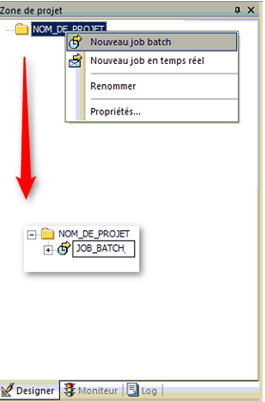
3. Créer un job dans la zone de projet
Dans la zone de projet, sélectionnez le nom du projet.
- Cliquez avec le bouton droit de la souris et sélectionnez Nouveau job Batch ou Job en temps réel.
- Modifiez le nom.
Le nom peut comporter des caractères alphanumériques et des traits de soulignement (_). Il ne peut pas contenir d’espaces.
Le logiciel ouvre un nouvel espace de travail où vous définissez le job
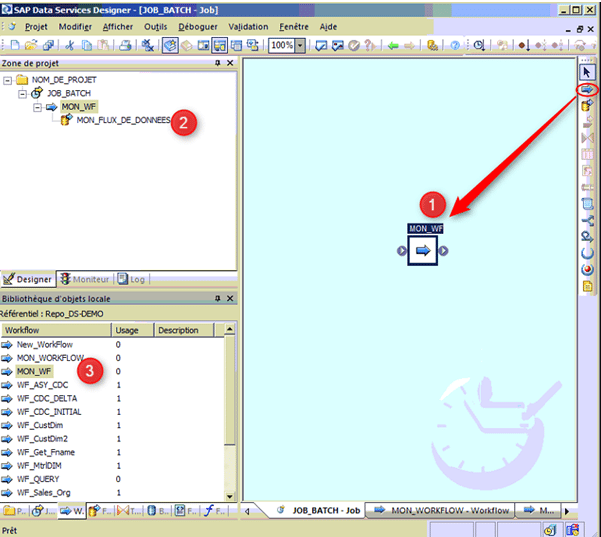
4. Création d’un « WorkFlow »
- Dans la zone de projet, cliquez sur le job créé.
- Sélectionnez l’icône « Workflow » dans la palette d’outils.
- Placez le «workflow » dans l’espace de travail du job.

5. Création d’un flux de donnée à l’aide de la palette d’outils
- Dans la zone de projet, cliquez sur le workflow créé.
- Sélectionnez l’icône du flux de données dans la palette d’outils.
- Placez le flux de données dans l’espace de travail du workflow.
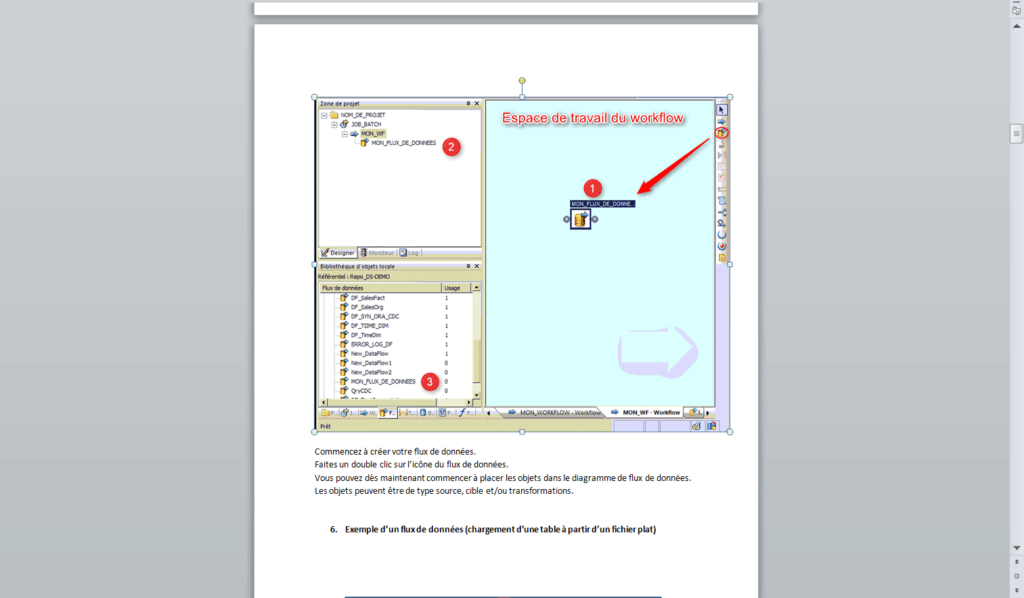
Commencez à créer votre flux de données.
- Faites un double clic sur l’icône du flux de données.
Vous pouvez dès maintenant commencer à placer les objets dans le diagramme de flux de données. Les objets peuvent être de type source, cible et/ou transformations.
Un flux de données extraie, transforme et charge les données. Tout ce qui a trait aux données, y compris la lecture des sources, la transformation des données et le chargement des cibles, se produit dans un flux de données. Les lignes qui connectent les objets dans un flux de données représentent le flux des données durant les étapes de transformation des données.
Après avoir défini un flux de données, il est possible de l’ajouter à un job ou à un workflow. A l’intérieur d’un workflow, un flux de données peut envoyer et recevoir des informations vers et depuis d’autres objets grâce aux paramètres d’entrée et de sortie.
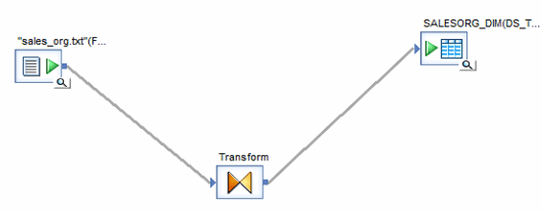
Dans cet exemple, vous allez renseigner une table « dimension » avec des données à partir d’un fichier plat.
Le flux de données comporte les éléments suivants :
- Un fichier plat (txt, csv,..)
- Une transformation (Query)
- Une table cible où les nouvelles lignes sont placées.
Vous indiquez le flux des données par ces composants en les connectant dans l’ordre dans lequel les données se déplacent dans ces derniers. Le flux de données obtenu ressemble à l’image ci-dessous
6. Création d’un nouveau format de fichier
- Depuis l’onglet Formats dans la bibliothèque d’objets locale, faites un clic droit sur Fichiers plats et sélectionnez Nouveau
- Pour l’option Type, sélectionnez :
|
Option | Définition |
| Délimité | pour un fichier qui utilise une séquence de caractères pour séparer les colonnes |
| Largeur fixe | pour un fichier qui utilise des largeurs spécifiées pour chaque colonne |
| Transport SAP | pour les objets de transport de données dans les flux de données des applications SAP |
| Texte non structuré | pour un ou plusieurs fichiers de texte non structuré à partir d’un répertoire. Le schéma est fixé pour ce type
|
| Binaire non structuré |
Dans ce tutoriel, nous allons utiliser un fichier de type délimité.
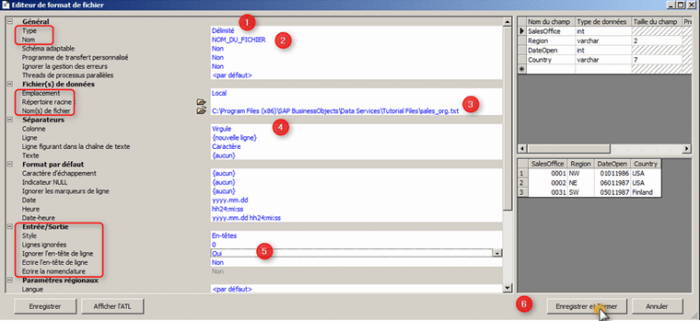
- Dans l’option Nom, attribuez un nom à votre fichier
- Sous Fichier(s) de données, définissez l’Emplacement, si le fichier se trouve sur l’ordinateur local du Designer, laissez l’option Local, sinon sélectionnez Job server, naviguez pour définir les options Répertoire racine et Fichier(s) pour spécifier l’exemple de fichier
- Sous Séparateurs, définissez le séparateur de la colonne.
- Sous Entrée/Sortie, définissez Ignorez l’en-tête de la ligne sur Oui si vous souhaitez utiliser la première ligne dans le fichier pour désigner les noms des champs
- Cliquez sur Enregistrer et Fermer pour enregistrer le modèle de format de fichier et fermer l’éditeur de format de fichier.
7. Définition d’une banque de données d’une base de données
Pour définir une banque de données de base de données, obtenez les privilèges d’accès à la base de données ou au système de fichier décrits par la banque de données. Une banque de données de bases de données représente des connexions uniques ou multiples.
Les bases de données supportées sont :
- IBM DB2
- Informix
- Microsoft SQL Server
- ORACLE,
- SQL Anywhere
Vous savez maintenant créer un WorkFlow, un DataFlow et une source de données de type fichier plat, si vous voulez apprendre à charger ce fichier dans une table de type Oracle 11g cliquez sur le lien suivant Partie 2

Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !