
Extraire les premières lignes d’un fichier délimité depuis le Studio Talend
Dans ce tutoriel vous apprendrez à créer depuis le Studio Talend un Job simple permettant l’extraction des premières lignes d’un fichier aux données délimitées pour les envoyer vers un fichier cible.
Prérequis :
- Avoir installé Studio Talend, la partie intégration ETL (Extract Transform Load) des solutions Talend.
- L’application gratuite TOSDI (Talend Open Studio for Data Integration) est suffisante pour disposer des composants utilisés dans ce tutoriel.
- Avoir étudié les tutoriels suivants : Créer un projet avec un Job simple depuis le Studio Talend, Se familiariser avec l’interface Talend Studio.
Composants ETL utilisés dans le traitement :
- Composants d’extraction ou chargement : tFileInputdelimited, tFileOutputdelimited.
- Composants de transformation : tMap, tFilterRows.
- Composants de médiation : Aucun.
- Composants d’affichage : Aucun.
Contexte :
Vous voulez extraire des lignes d’un fichier CSV source contenant des données de vente et les envoyer dans un fichier CSV cible.
Voilà les 15 premières lignes du fichier CSV source :
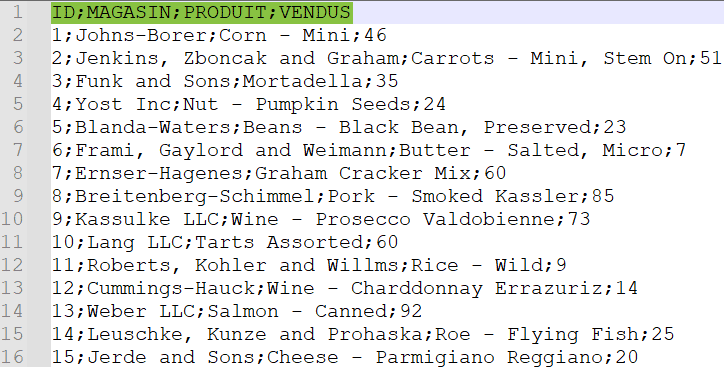
Ce fichier CSV contient une première ligne contenant les noms de colonnes, les lignes suivantes contiennent les données. Toutes ces informations sont délimitées par des points virgule.
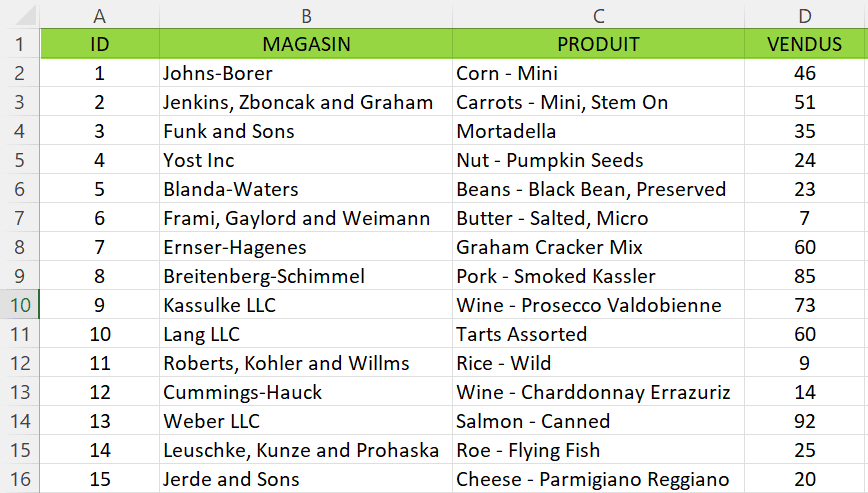
Pour plus de clarté voilà le même fichier ouvert depuis Excel en indiquant le délimiteur « Point virgule ». Ce fichier contient des informations de nombre de ventes de divers produits par magasin.
Nous allons développer depuis le Studio Talend un Job simple extrayant les 10 premières lignes de ce fichier pour les envoyer vers un fichier cible.

Solution :
Dans un premier temps nous allons créer les structures de métadonnées qui nous permettront de créer les composants source et cible du traitement.
Depuis le Studio Talend déroulez la section « Métadonnées » du référentiel de projet puis faites un clic droit sur « Fichier délimité » suivi de « Ajouter« . Nommez votre structure de métadonnées avec un préfixe indiquant le type de fichier (CSV_VENTES) puis indiquez un objectif et une description et cliquez sur « Suivant ». L’ajout du préfixe est facultatif mais c’est une bonne pratique de convention de nommage :

Indiquez quel est le fichier qui va être lu. Un aperçu du contenu du fichier est disponible :

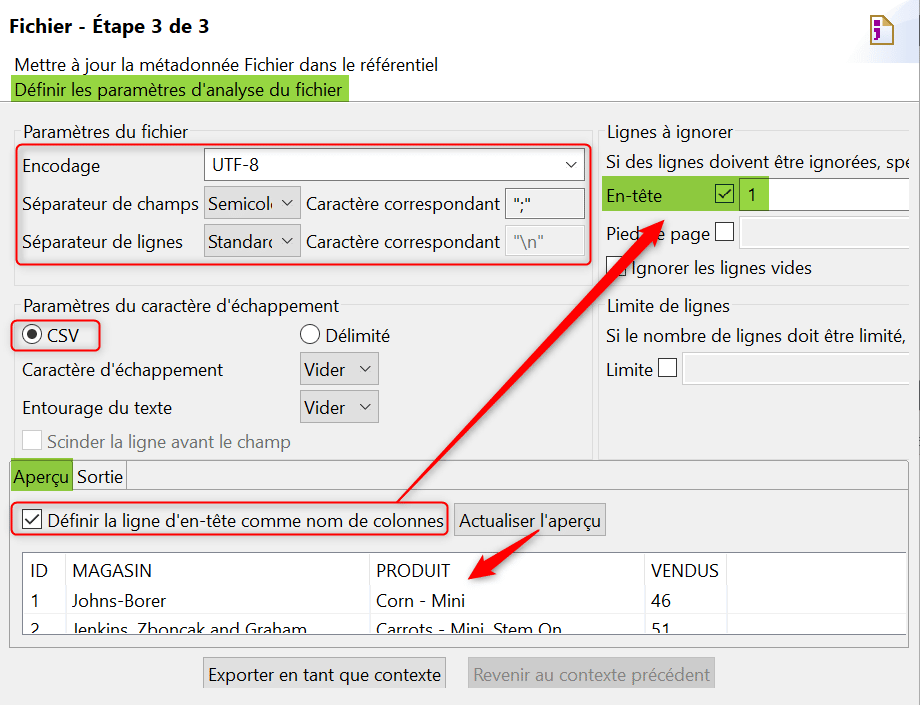
Indiquez le type d’encodage du fichier (UTF-8) et les séparateur des champs et des lignes à lire (point virgule et retour à la ligne n). Indiquez un caractère d’échappement de type CSV puis définissez la ligne d’en-tête comme nom de colonnes et cliquez sur « Actualiser l’aperçu« . Une fois l’aperçu généré vérifiez que la structure selon laquelle le fichier est lu est correcte :
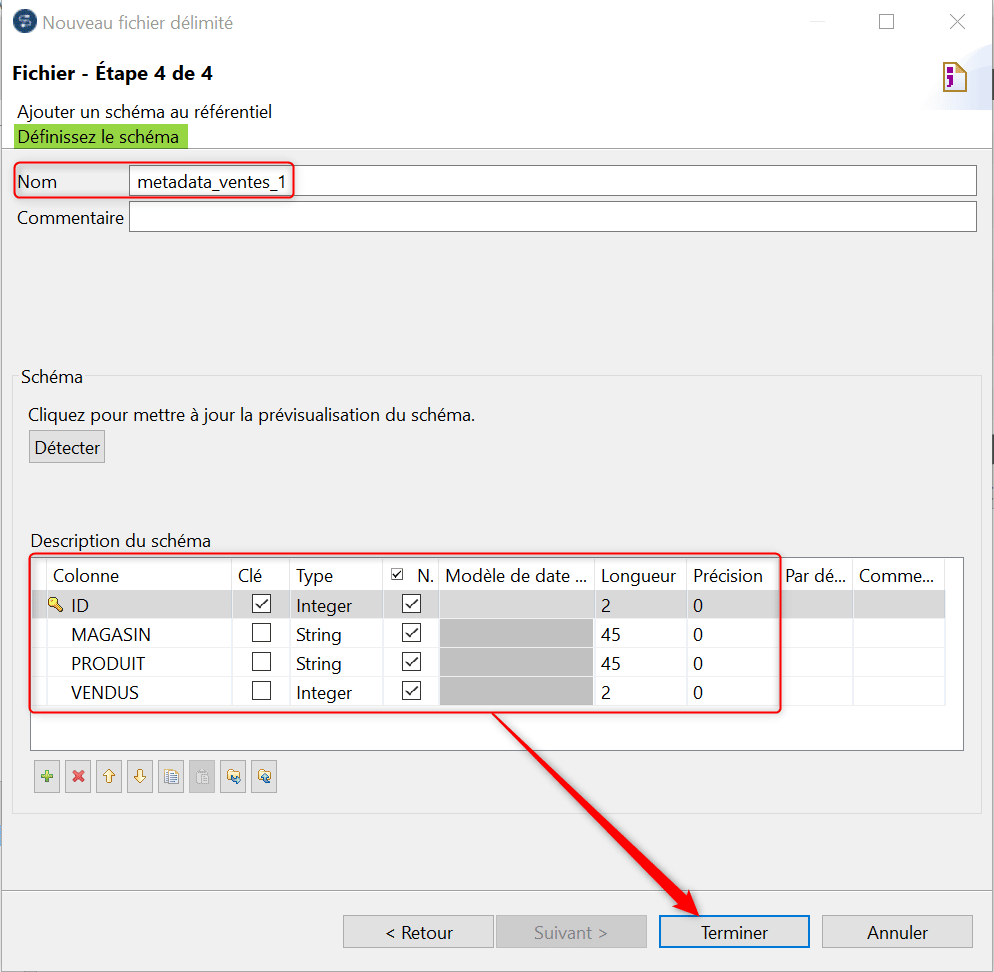
Indiquez le nom du schéma de données qui sera généré (metadata_ventes_1) puis dans la description du schéma apportez les corrections nécessaires sur les types de données lus, leur longueur et leur précision quand il s’agit de décimaux. Cliquez sur « Terminer » pour valider la création du schéma de données :
Créez un nouveau Job standard nommé « JOB_LECTURE_FICHIER » :
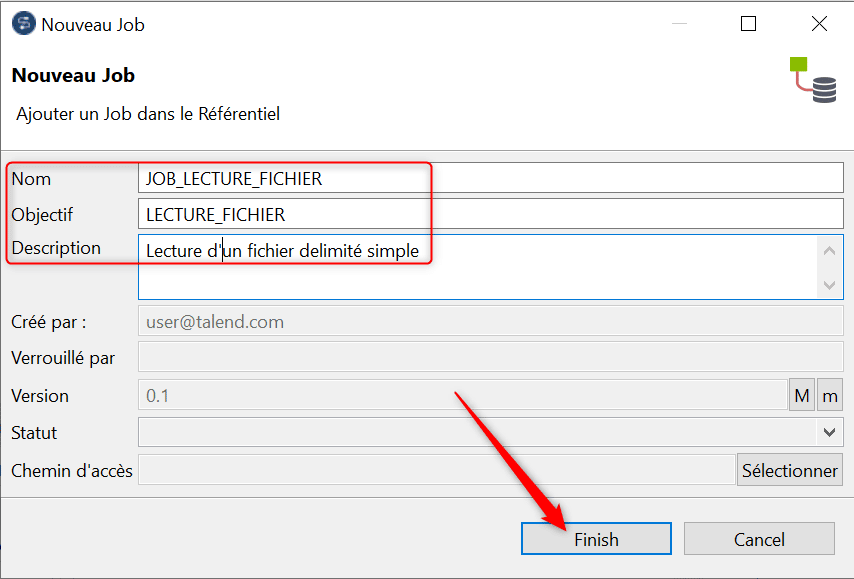
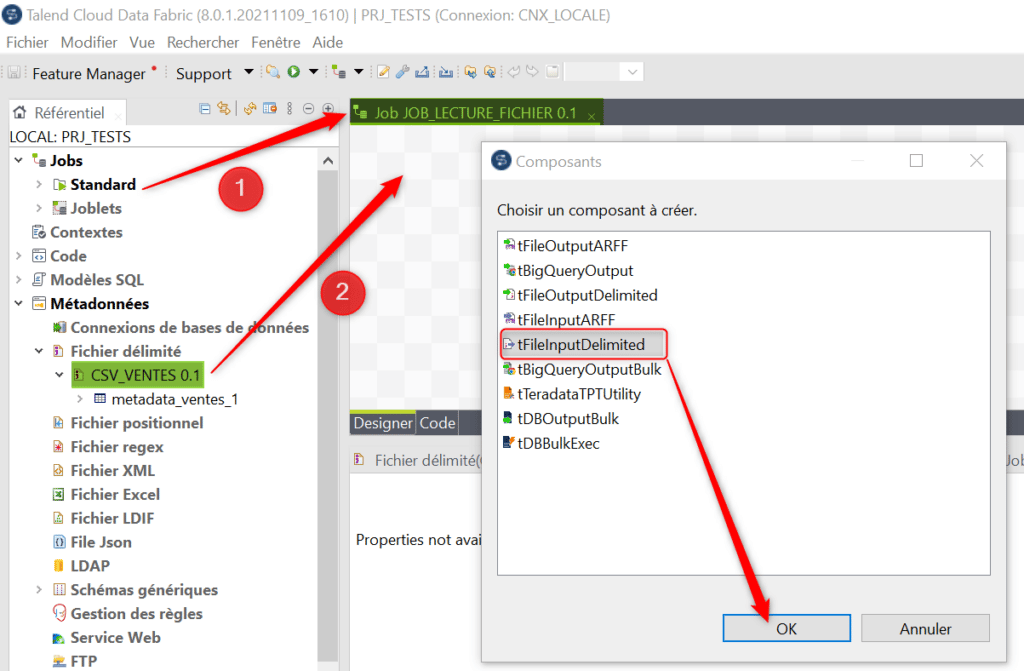
Double cliquez sur le Job afin de l’ouvrir dans l’espace de travail (1) puis cliquez – déposez l’objet de métadonnées CSV_VENTES (2) à l’intérieur du Job pour l’insérer en tant que composant tFileInputDelimited :
Sélectionnez par un clic le composant (1) puis cliquez sur « Composant » afin d’afficher ses propriétés (2). Le schéma des données source gérées par le composant est indiqué comme venant du référentiel depuis les métadonnées CSV_VENTES. Vous pouvez cependant modifier le schéma utilisé par le composant (3) pour choisir un autre schéma du référentiel ou bien basculer en mode Built – In pour définir votre propre schéma manuellement (4) :

Depuis l’onglet « Paramètres avancés » de la vue Composant vous pouvez changer divers paramètres de lecture du fichier (gestion des espaces, encodage etc..). Ces changements concerneront le composant utilisé dans le flux et non les métadonnées qu’il utilise définies dans le référentiel :

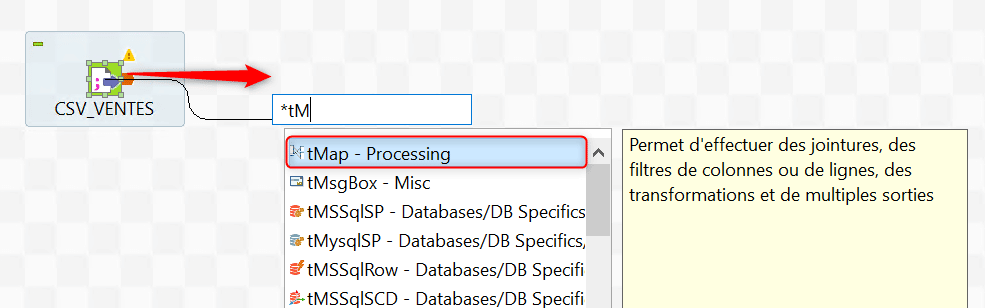
Ajoutez un composant tMap au traitement par une recherche suivie d’un glissez – déposer depuis la Palette, puis reliez le composant de lecture de fichier à ce tMap. Selectionnez le tMap puis allez dans la vue Composant et dans l’onglet « Vue » et donnez un nom au tMap :

Afin d’insérer le tMap vous pouvez aussi directement créer le lien depuis le composant source puis lâcher la souris dans l’espace de travail. Une liste des composants que vous pouvez lier sera proposée et vous pourrez faire une recherche. Cliquez sur le composant tMap afin de l’insérer :
Double cliquez sur le composant tMap afin d’ouvrir sa fenêtre de mapping puis créez une nouvelle sortie du tMap nommée « EXTRACTION » :
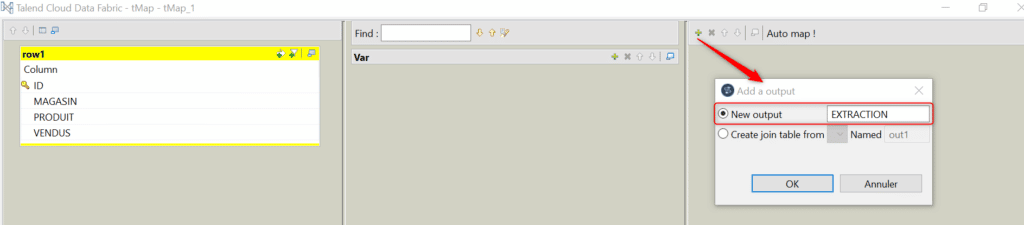
Par un cliquer déposer mappez l’ensemble des champs d’entrée du tMap vers la sortie (1) et depuis la fenêtre du schéma de sortie ajoutez un champs de type Integer et nommé « NUM_LIGNE » (2) :

Le champs NUM_LIGNE va nous permettre de numéroter les lignes du fichier dans leur ordre de passage dans le tMap. Grâce à un composant de filtre vous ne conserverez ensuite que les 10 premières lignes. A cette fin ouvrez le constructeur d’expression du champs NUM_LIGNE puis ajoutez la fonction Numeric.sequence(« NUM », 1, 1) qui va numéroter les lignes en commençant par 1 et avec un incrément de 1 :

Après avoir cliqué deux fois sur OK afin de valider les changements effectués, insérez un composant tFilterRows puis faites un clic droit sur le tMap et sélectionnez EXTRACTION comme ligne de sortie. Reliez ensuite la sortie EXTRACTION au composant tFilterRows :
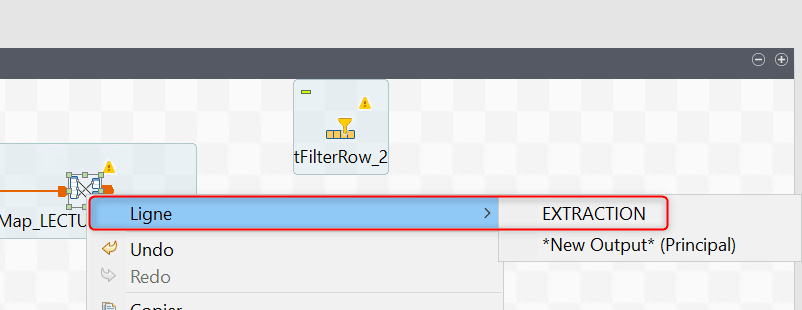
Attention si vous créez un lien directement depuis le tMap vers le composant suivant sans sélection de EXTRACTION, c’est une nouvelle sortie du tMap qui va vous être proposée.
Après avoir renommé le composant de filtre allez dans sa vue Composant puis ajoutez une condition de filtre NUM_LIGNE inférieur ou égal à 10 afin que seules les dix premières lignes du fichier source soient conservées :
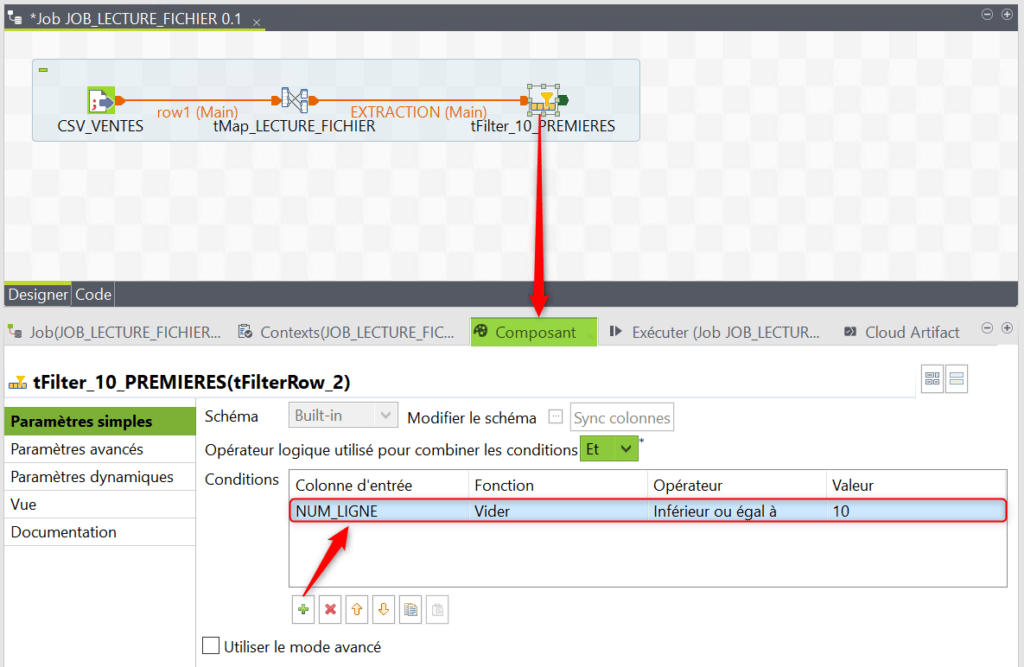
Créez un nouveau lien depuis le composant de filtre vers un composant tFileOutputDelimited :
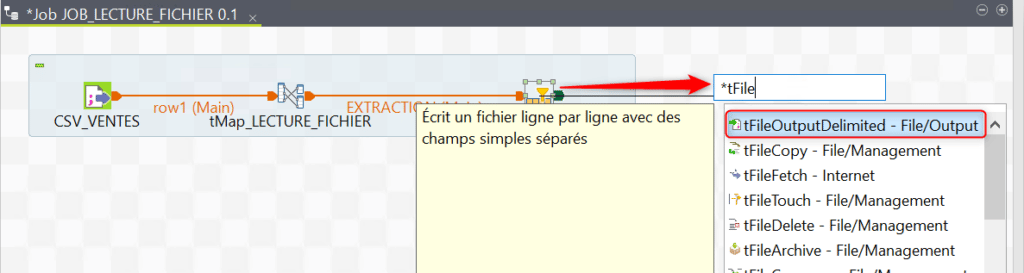
Nommez le composant de sortie puis dans sa vue Composant indiquez le fichier de sortie. Précisez que vous voulez inclure l’entête des champs dans ce fichier de sortie :
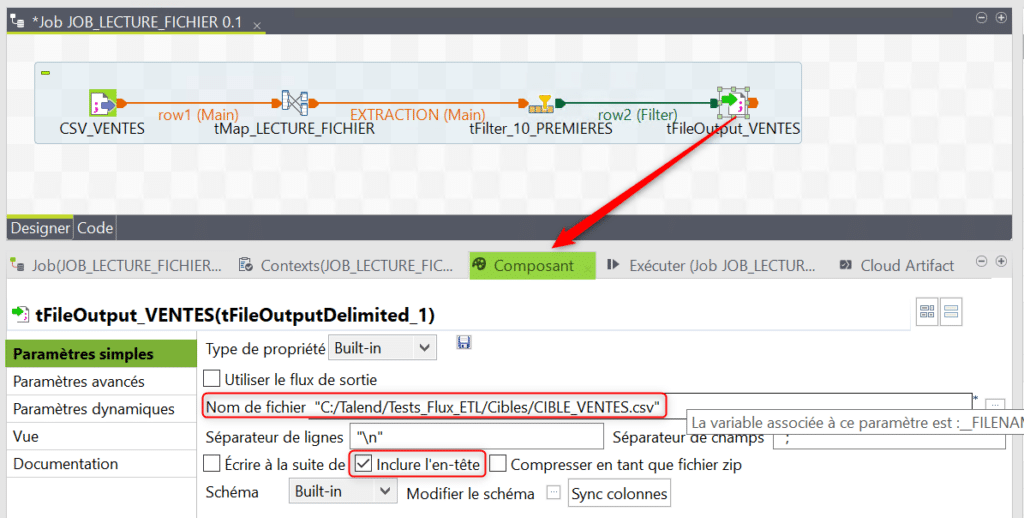
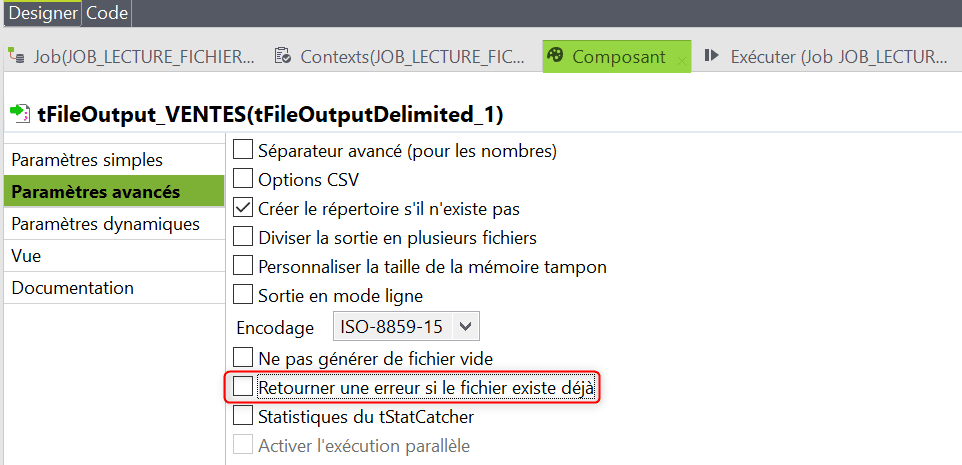
Dans les paramètres avancés décochez l’option par défaut « Retourner une erreur si le fichier existe déjà« . Ainsi si vous exécutez plusieurs fois le Job le fichier cible sera remplacé à chaque fois :
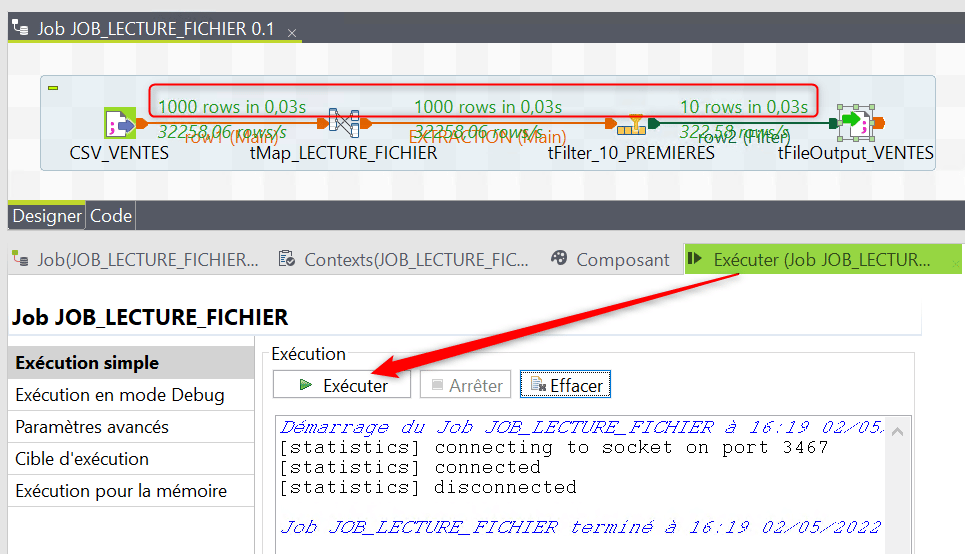
Après avoir sauvegardé votre Job allez dans la vue « Exécuter » puis lancez l’exécution du Job. Vérifiez dans les logs que l’exécution se termine et qu’aucune erreur n’est signalée :
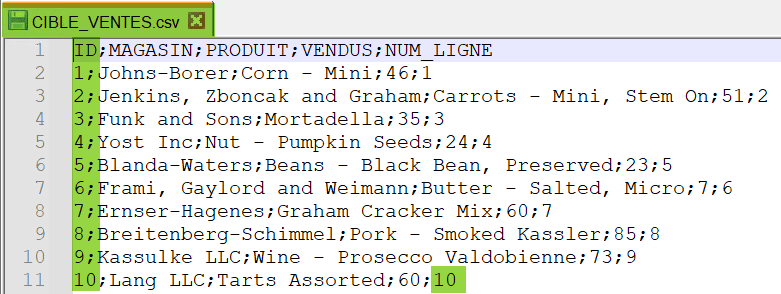
Le fichier cible contient bien les 10 premières lignes extraites depuis le fichier source. Remarquez que nous aurions pu nous passer du tMap car le champs ID étant lui même incrémenté dans le fichier de départ, il aurait pu être utilisé dans la condition du filtre :
Vous savez désormais comment créer depuis le Studio Talend un Job simple permettant la lecture d’un fichier aux données délimitées.

Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !