
Comment stocker les logs d’erreurs dans une BDD (MS SQL SERVER 2012)
Ce tutoriel, vous guidera dans la gestion personnalisée de logs d’erreurs SAP Data Services et le stockage associé dans une base de données de type MS SQL SERVER 2012.
• Prérequis : Accès à une base de données de type MS SQL SERVER 2012 ou autre, un fichier texte contenant les données brutes
• Version: SAP Data Services 4.2
• Application: Data Services Designer
Etape 1 : Créer un job Batch «erreurLogJob » dans SAP Data Services Designer.
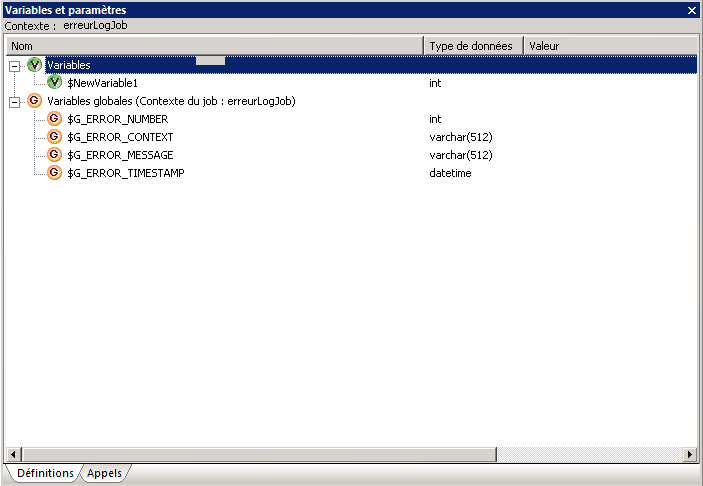
Etape 2 : Déclarer quatre variables globales liées au job « erreurLogJob ».
Etape 3 : Glissez et déposez les composants suivants dans l’espace de travail et connectez-les comme indiqué dans la figure ci-dessous. Dans l’espace du travail du « DataFlow » vous pouvez utiliser un flux simulant une alimentation entre une source et une cible.
- Sélectionnez l’icône du flux de données dans la palette d’outils.
- Placez le flux de données dans l’espace de travail du Job.
- Placez un bloc TRY/CATCH
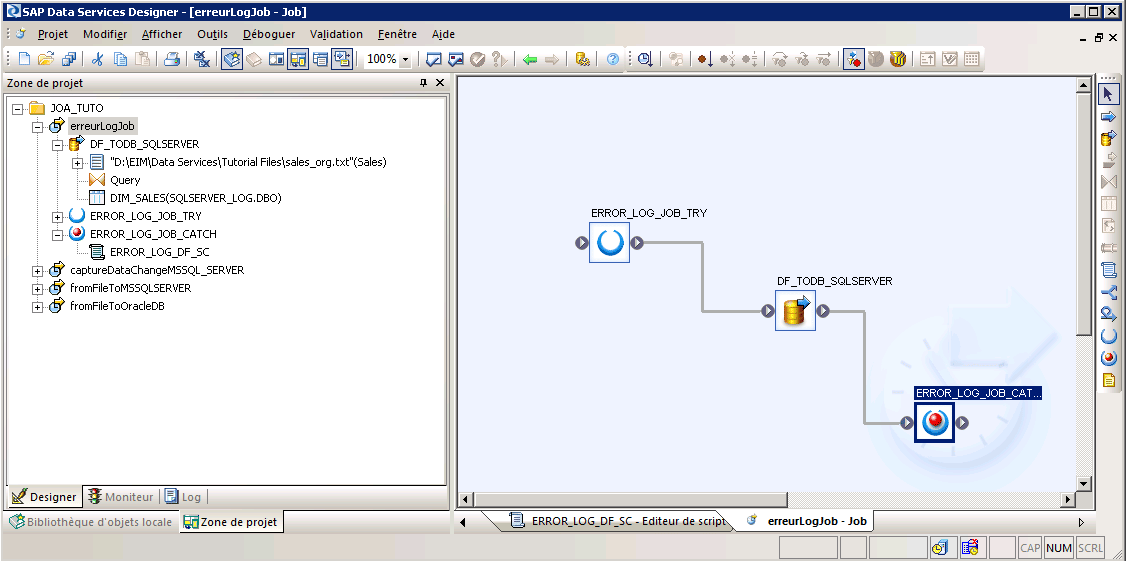
Etape 4 : Editez le bloc CATCH et déposez un script et nommé le « ERROR_LOG_DF_SC ».

Etape 5 : Ouvrir le script et écrire le code tel qu’il apparait dans la figure ci-dessous

Le script ci-dessous affecte les variables globales précédemment crées à des fonctions natives à SAP Data Services (Exemple error_number(), error_context(),..) Et appelle ainsi une fonction personnalisée pour enregistrer les erreurs dans une table permanente. Cette fonction n’existe pas pour le moment, nous allons la créer dans les étapes ultérieures.
Etape 6 : Créer la fonction personnalisée « CF_ERROR_LOG »
Dans Bibliothèque d’objets locales, dans l’onglet « Fonctions » :
- faites un clic droit sur « Fonctions personnalisées, puis « Nouveau »
- Donnez le nom « CF_ERROR_LOG » à votre fonction puis cliquez « suivant »
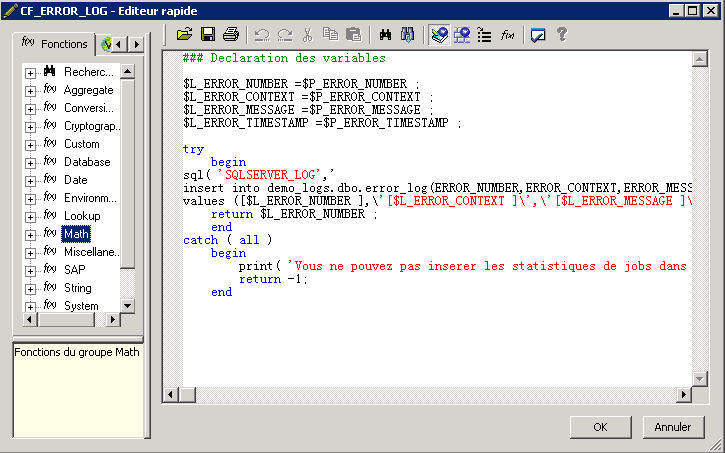
- En cliquant sur suivant l’Editeurs Rapide de la fonction personnalisée se lancera
- Ecrivez le code suivant tel qu’indiqué dans la figure ci-dessous
Etape 7 : Maintenant la fonction est défini, nous avons à disposition une instance MSSQL SERVER pour faire la capture des erreurs dans une table dédiée à cet effet. Créons donc la table « ERROR_LOG » afin de pouvoir stocker les informations sur les erreurs.
CREATE DATABASE DEMO_LOGS ;
CREATE TABLE DEMO_LOGS.[dbo].[ERROR_LOG](
[SEQ_NO] [int] IDENTITY(1,1) NOT NULL,
[ERROR_NUMBER] [int] NULL,
[ERROR_CONTEXT] [varchar](512) NULL,
[ERROR_MESSAGE] [varchar](512) NULL,
[ERROR_TIMESTAMP] [VARCHAR] (512) NULL
);
Vous pouvez changer la banque de données selon vos besoins. Nous avons ici dans cet exemple une banque de données intitulée « SQL_SERVER_LOG » que nous utilisons dans une fonction personnalisée.
Etape 8 : Faites en sorte que votre « DataFlow » soit en erreur. Dans notre cas par exemple nous avons essayé de générer une erreur sur l’unicité de l’enregistrement.
Dans le flux de sortie, est défini une clé primaire. Lors de la première exécution le job ne plante pas, par contre si on ré exécute le job à plusieurs reprises, une erreur de type « Duplicate key » sera générée.
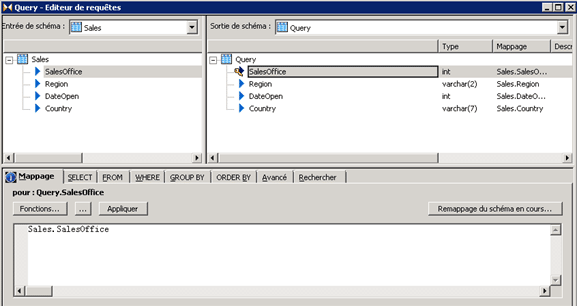
Etape 9 : Vous pouvez à présent exécuter le job « erreurLogJob », vous allez avoir une erreur « Duplicate Key », vérifiez si les erreurs ont été stockées en base de données.

Dans la table « dbo.ERROR_LOG » nous avons ceci :
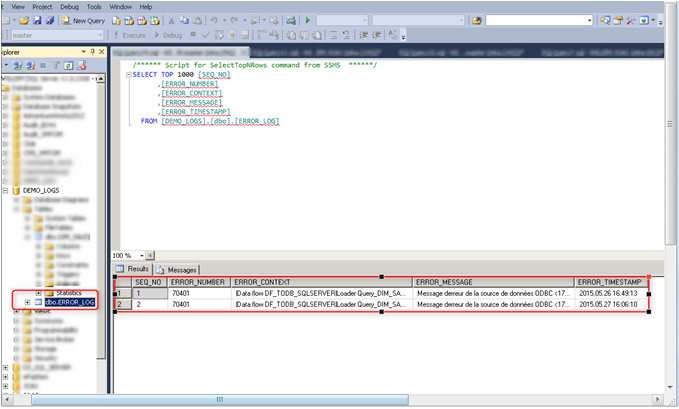
En éditant le champ «ERROR_MESSAGE » vous obtenez ceci :


Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !