
Traiter tous les fichiers pertinents d’un répertoire avec le composant tFileList
Dans ce tutoriel vous apprendrez à extraire successivement les données de chacun des fichiers d’un répertoire dont le nom obéit à un pattern particulier. Celà sera l’occasion d’utiliser le lien de type « Iterate » permettant d’exécuter en boucle un même traitement autant de fois qu’un composant itératif l’a décidé.
Prérequis :
- Avoir installé Studio Talend, la partie intégration ETL (Extract Transform Load) des solutions Talend.
- L’application gratuite TOSDI (Talend Open Studio for Data Integration) est suffisante pour disposer des composants utilisés dans ce tutoriel.
- Avoir une compréhension de l’utilisation de fonctions dans un ETL ou un programme.
- Afin de se familiariser avec l’utilisation du composant tFileInputDelimited, avoir étudié le tutoriel suivant : Extraire les première lignes d’un fichier délimité depuis le Studio Talend.
Composants ETL utilisés dans le traitement :
tFileList, tFileInputDelimited, tSetGlobalVar, tMap, tFileOutputDelimited.
Fonctions utilisées dans le traitement :
TalendDate.getCurrentDate, TalendDate.formatDate, globalMap.get, substring.
Contexte
Une application source envoie régulièrement des fichiers au format « Commande_timestamp » dans un répertoire source présent sur la machine hôte Talend. Le répertoire contient d’autres fichiers devant être ignorés par le traitement ETL :
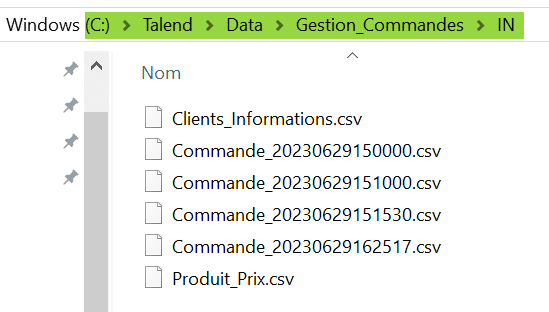
Nous voulons appliquer un même mapping à tous les fichiers de commandes de ce répertoire puis ajouter à leur nom le timestamp de l’instant de leur traitement et stocker le résultat dans des fichiers CSV au sein d’un répertoire cible.
Solution :
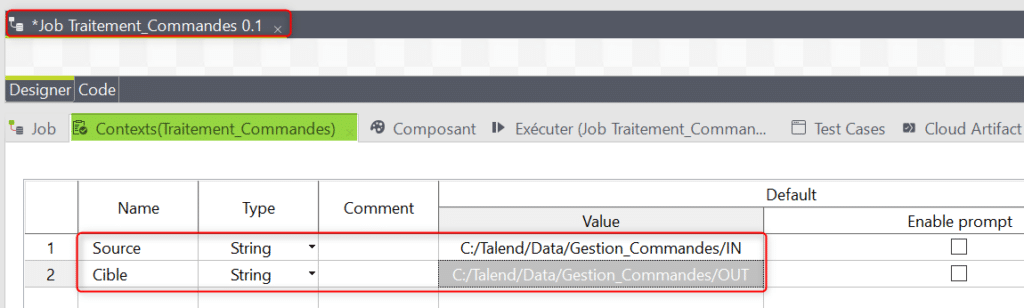
Dans un premier temps créez le Job Traitement_Commandes puis les variables de contexte qu’il va utiliser. Dans notre cas il n’y a que deux variables de contexte :
- Le chemin du répertoire source placé dans la variable « Source ».
- Le chemin du répertoire cible placé dans la variable « Cible ».
Ensuite insérez recherchez le composant tFileList dans la Palette puis insérez le dans votre Job par un cliqué – déposé :
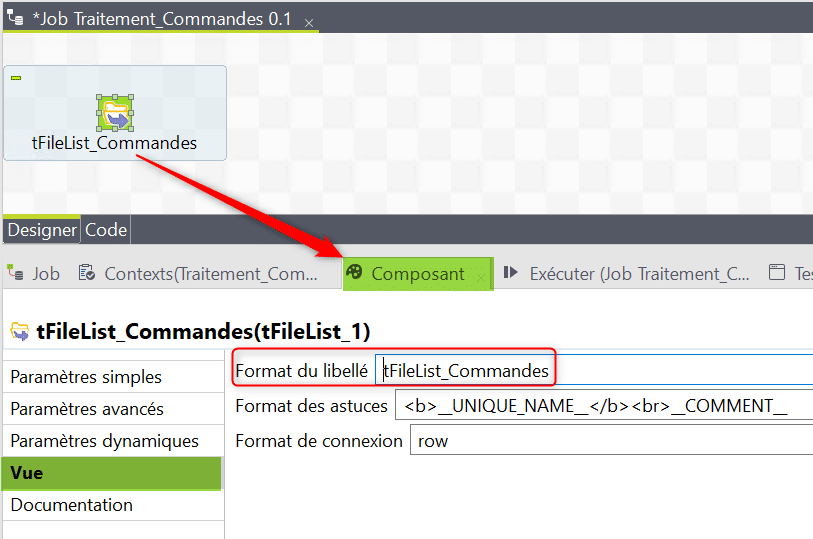
Cliquez sur le tFileList puis allez dans la vue Composant. Allez dans la section Vue puis renommez le composant en ajoutant « _Commandes ». C’est en effet une bonne pratique d’ajouter la fonction d’un composant dans votre Job ETL en plus de son nom, ainsi un développeur découvrant votre Job en comprendra intuitivement les étapes :
Le composant tFileList va vous permettre de lister tous les fichiers du répertoire source dont le nom obéit à un pattern que nous allons spécifier. Le reste du Job sera alors chargé d’itérer sur la liste obtenue.
Revenez ensuite dans la section « Paramètres simples » du tFileList puis indiquez le répertoire dans lequel les fichiers source vont être recherchés (1). Vous pouvez utiliser le contexte défini en écrivant « context. » suivi de « Ctrl + Espace » afin d’aller chercher votre variable de contexte. Indiquez le masque de fichier (2). Il s’agit du pattern selon lequel les fichiers source à lister pour traitement seront identifiés. Enfin vous pouvez indiquer que la liste doit être généré selon l’ordre alphabétique croissant des noms de fichiers testés (3). Dans notre cas celà permettra de les lister puis les traiter dans l’ordre de leur timestamp :
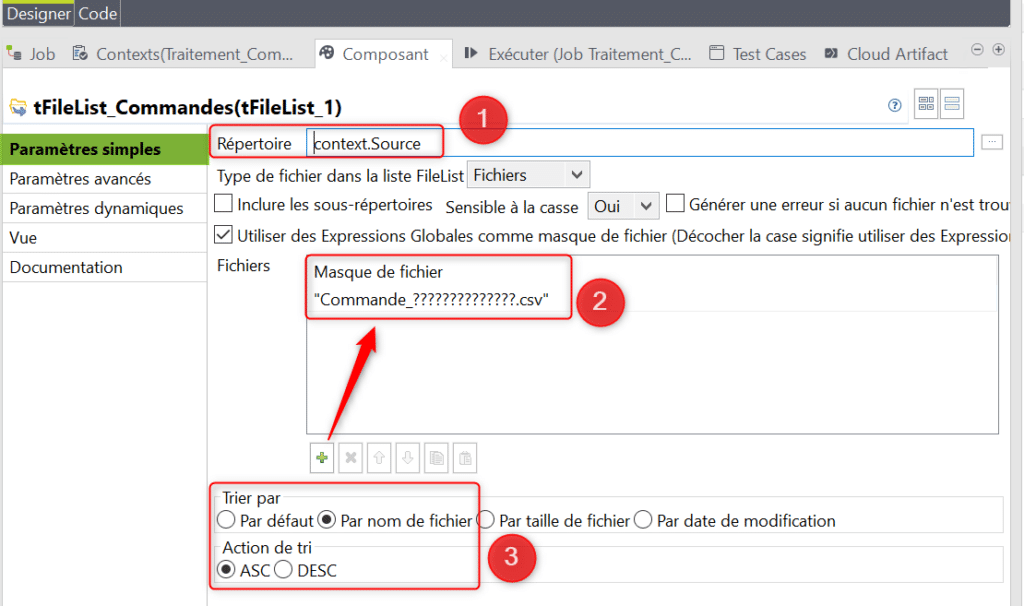
Faites un clic droit sur le tFileList suivi de « Itérer » afin de construire un lien de type itératif puis cliquez dans l’espace devant le tFileList :
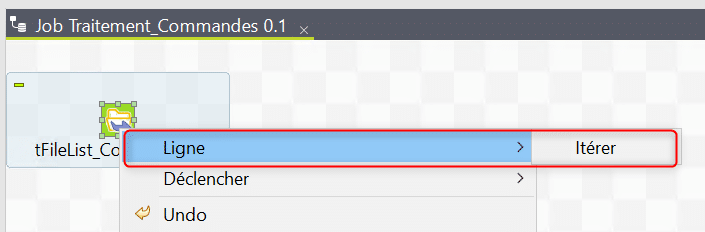
Recherchez puis insérez un composant tSetGlobalVar. Renommez le toujours afin de suivre les bonnes pratiques :
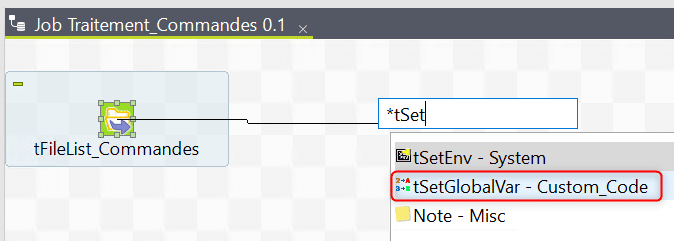
Au sein du composant tSetGlobalVar créez la définition d’une variable timestamp qui va stocker la valeur du timestamp au moment du traitement du fichier. Le composant tSetGlobalVar sera invoqué autant de fois qu’il y a de fichiers à traiter identifiés dans la liste générée par le tFileList :
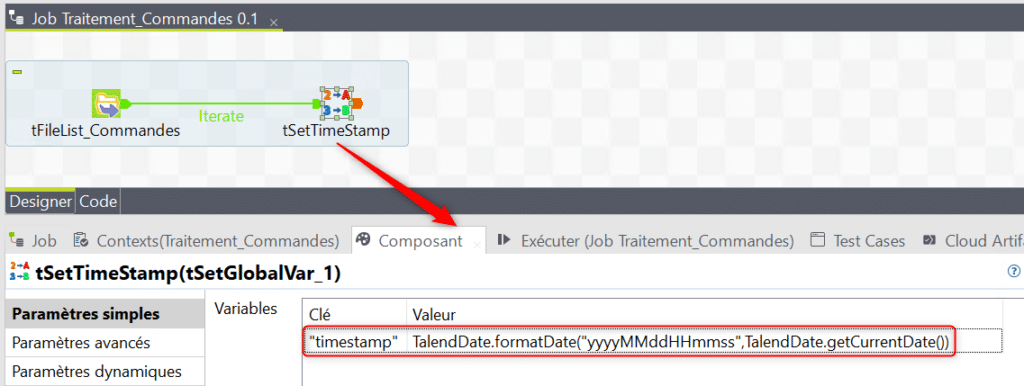
La génération du Timestamp fonctionne de la manière suivante :
- La fonction TalendDate.getCurrentDate permet de récupérer la date à l’instant du traitement.
- La fonction TalendDate.formatDate permet de formater la date obtenue afin de la stocker sous la forme d’un timestamp.
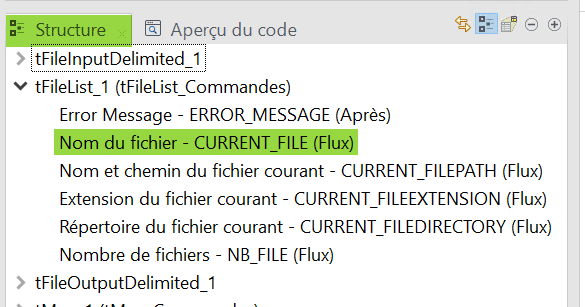
Insérez un composant tFileInputDelimited puis allez dans sa vue Composant. Depuis le cadre « Structure » déroulez la liste des variables globales automatiquement générées par le composant tFileList de votre traitement. Glissez – déposez la variable CURRENT_FILEPATH dans le nom de fichier lu par votre composant tFileInputDelimited. Cette variable stocke pour l’itération en cours la valeur du chemin complet du fichier source identifié par le tFileList et la fonction de récupération de sa valeur est automatiquement écrite :
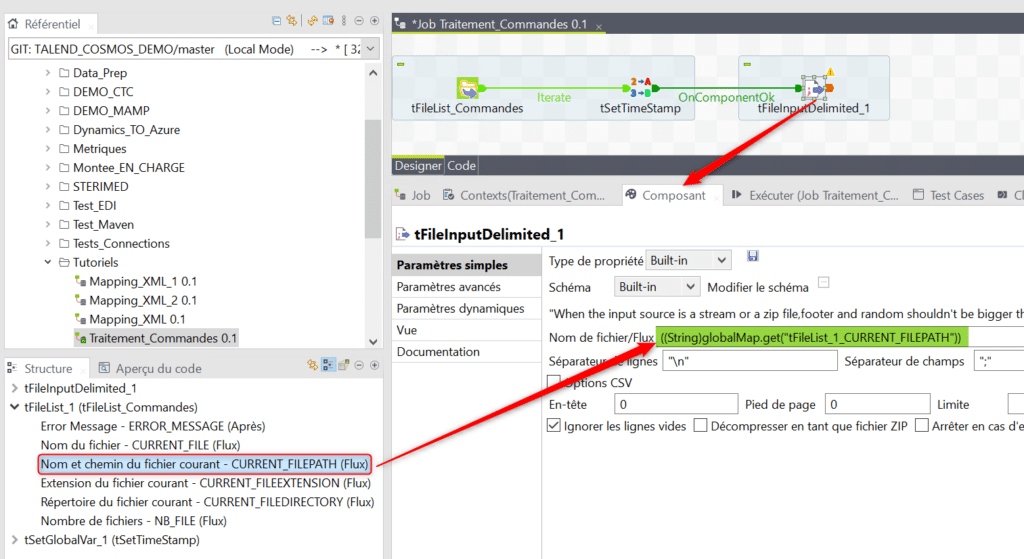
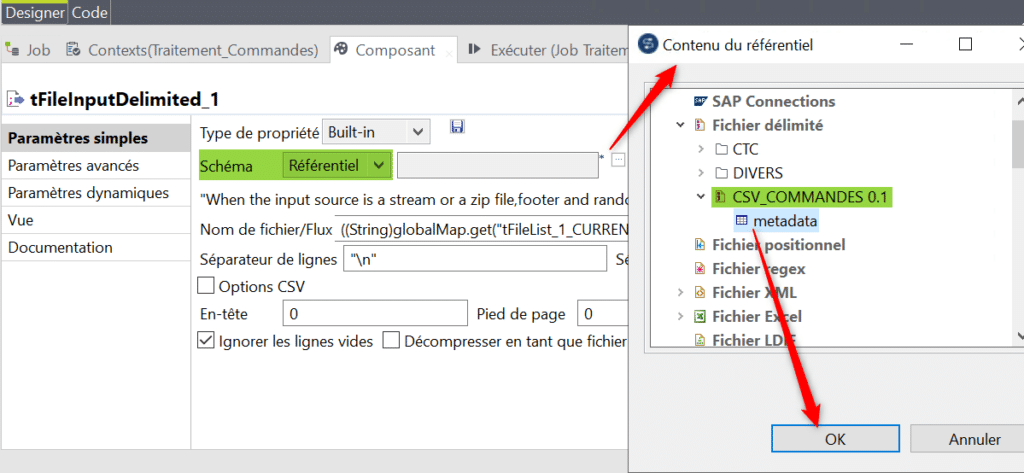
Vous devez maintenant définir le bon schéma dans votre tFileInputDelimited, soit manuellement (en Built In) soit en allant chercher ce schéma depuis les métadonnées du référentiel :
Ajoutez ensuite un tMap à votre traitement afin d’appliquer le mapping voulu à vos données d’entrée puis reliez la sortie du tMap à un composant tFileOutputDelimited.
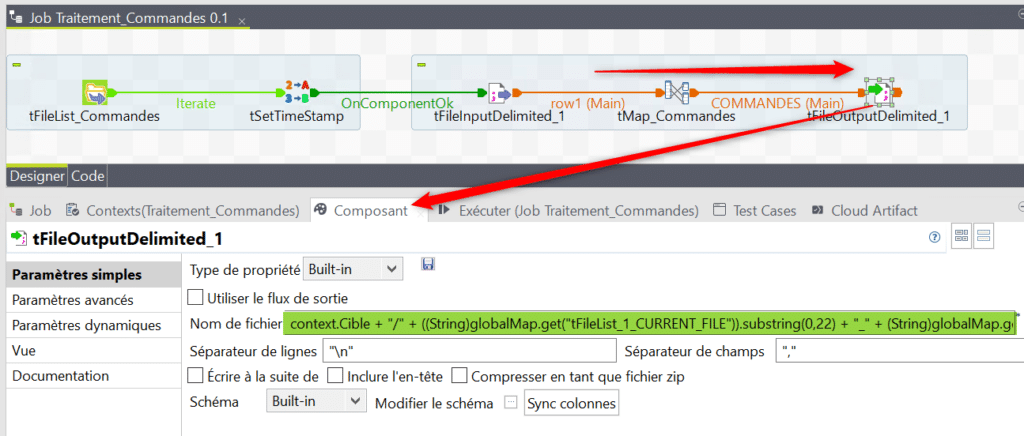
Afin de générer le chemin et le nom du fichier cible nous allons cette fois utiliser depuis les Structures la variable CURRENT_FILE mise à jour à chaque itération par le tFileList :
Le problème est que CURRENT_FILE inclut l’extension du fichier, or nous voulons concaténer le timestamp que nous avons généré au nom du fichier source pour générer la sortie. Nous devons donc utiliser la fonction substring pour extraire le nom du fichier de l’itération courante sans son extension, avant de concaténer le résultat avec la valeur du timestamp que nous avons généré pour l’itération courante. Voilà l’expression complète qui doit être insérée en tant que nom de fichier cible pour le tFileOutputDelimited :
context.Cible + « / » + ((String)globalMap.get(« tFileList_1_CURRENT_FILE »)).substring(0,22) + « _ » + (String)globalMap.get(« timestamp ») + « .csv »
Vérifier que le code de votre Job ne contient pas d’erreur puis lancez son exécution. Allez vérifier dans le répertoire cible que les fichiers de sortie ont été générés avec un nom correct incluant le timestamp d’origine correspondant à l’arrivée de la donnée source concaténé au timestamp que vous avez généré lors du traitement de ces données source :
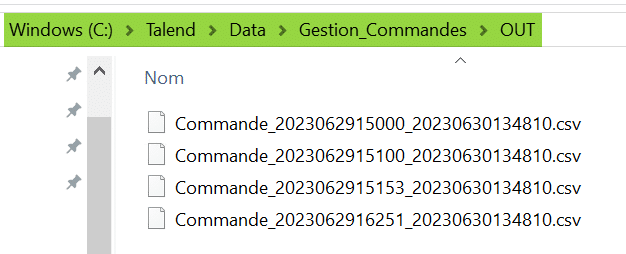
Vous savez désormais comment développer un Job qui extrait de manière itérative les données de chacun des fichiers d’un répertoire dont le nom obéit à un pattern particulier.

Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !