
Ingestion dans Fabric : Dataflows Gen2 vs Pipelines :
Temps de lecture : 2 minutes
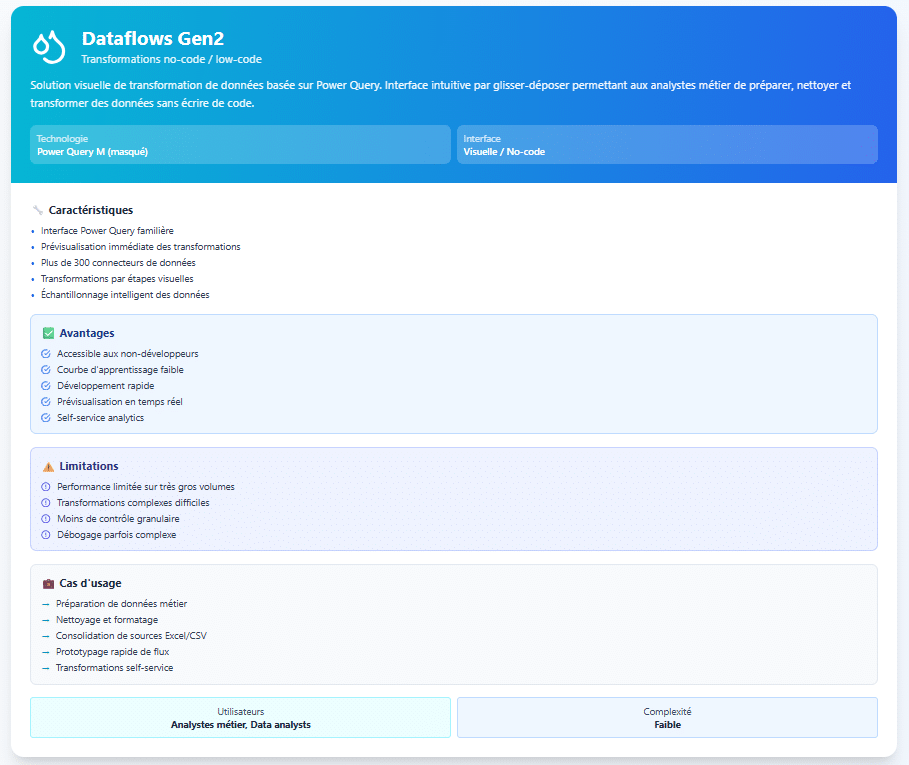
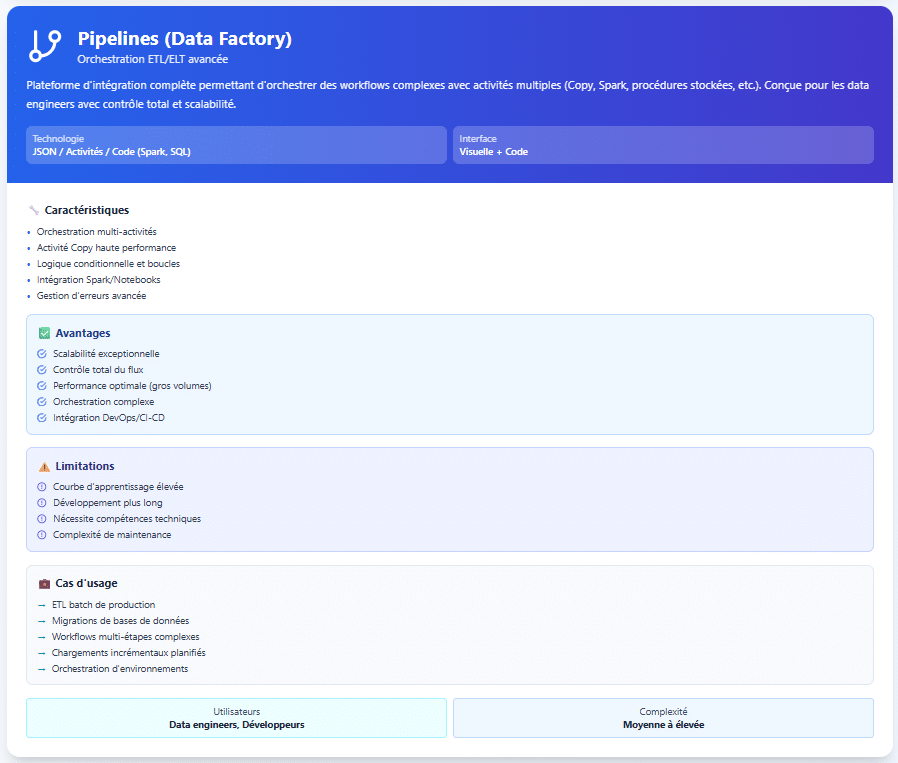
| Critère | DataFlow Gen2 | Pipelines |
| Rôle | Préparer les données sans code (Power Query). | Orchestrer des traitements de bout en bout. |
| Transformations | Interface clics (filtres, jointures, colonnes calculées). | Copier, lancer des scripts, exécuter des notebooks, utiliser T-SQL, appeler des API web. |
| Planification | Actualisations simples et régulières. | Déclencheurs horaires/événementiels, dépendances entre tâches. |
| Volumes & performance | Adapté à des volumes faibles à intermédiaires et APIs lentes. | Conçu pour des volumes importants et le respect d’horaires et de délais garantis (engagements de service). |
| Suivi & alertes | Suivi de réussite/échec d’un rafraîchissement. | Historique détaillé, alertes et reprises automatiques. |
| Déploiement & changements | Simple à réutiliser ; peu de paramètres. | Configuré par environnement (développement, test, production) et davantage orienté mise en production. |
| Sécurité & gouvernance | Idéal pour self-service encadré (équipes BI). | Rôles d’exploitation et gestion de secrets/connexions. |
| Coût & exploitation | Coût par rafraîchissement ; faible maintenance. | Coût par exécution ; opérations et supervision plus riches. |
| à éviter | Logique métier complexe et longues chaînes d’étapes. | Mobiliser un pipeline pour une petite retouche simple. |
| Exemple | Import CRM/Excel → nettoyage → écritures vers Lakehouse. | Copie base on-premises → contrôle qualité → chargement Warehouse → notification. |
Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !