
Utiliser le composant Case pour classer des données sources selon des critères
Dans ce tutoriel vous apprendrez avec SAP Data Integrator comment classer grâce à un composant « Case » les lignes d’un flux de données selon le résultat d’un test effectué sur la valeur d’un des champs d’une table source.
Prérequis
- Avoir installé IPS (Information Platform Service) et Data Integrator.
- Avoir crée un référentiel local hébergeant les objets utilisés pour développer avec le designer de Data Integrator. Consultez le tutoriel suivant pour apprendre comment créer une base pour votre référentiel local puis ce tutoriel pour apprendre comment créer et déclarer le référentiel local lui – même.
- Disposer d’un base de donnée crée sous Microsoft SQL Server. Dans notre cas nous utilisons une base de données SPL_Warehouse constituant un Univers sur des faits de commandes.
- Disposer d’un compte utilisateur avec des droits suffisant.
- Savoir créer un projet sous Data Integrator Designer. Consultez le tutoriel suivant dans lequel est détaillé la création d’un projet contenant un Job permettant le chargement d’une table à partir d’un fichier plat.
- Savoir créer une banque de données permettant d’utiliser des tables d’une base de données comme sources et/ou cibles. Consultez le tutoriel suivant concernant la création d’un banque de données (base Oracle) et l’import de ses tables.
- Savoir comment valider la vue des constituants d’un Job et tester son exécution.
- Version: SAP Data Integrator 4.2 SP10.
- Applications : Data Integrator Designer, Microsoft SQL Server 2012.
Contexte
Nous disposons parmi les tables de notre base de données SPL_Warehouse une table INVENTORY historisant les valeurs de stocks des produits. Nous voulons effectuer une analyse différenciée des lignes contenues dans cette table selon trois catégories de valeur du stock : bas (moins de 1000), moyen (entre 1000 et 10000) et bon (supérieur à 10000).
Ce tutoriel porte sur la phase de préparation des données source issues de la table INVENTORY, réalisé par un Dataflow initial utilisant un composant Case générant trois sorties correspondant aux trois catégories de stocks présentées ci – dessus.
Selon la valeur du stock pour une date et un produit donné les lignes extraites depuis INVENTORY seront ainsi envoyées dans trois tables différentes qui pourront être dans les Dataflow suivant de notre Workflow traitées chacune différemment.
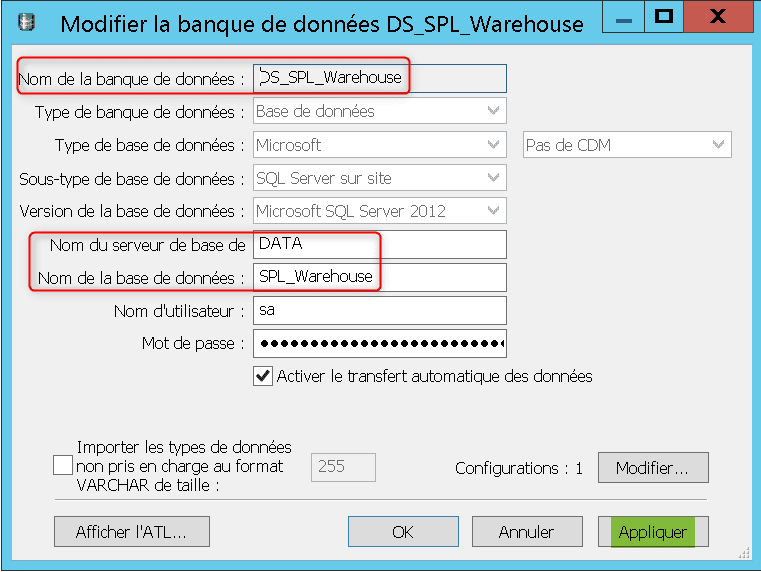
Dans un premier temps créez dans votre référentiel local une banque de données permettant d’accéder à la base SPL_Warehouse :
Puis créez un projet ayant la structure suivante :

Le Dataflow DF_SPLW_PRODUIT sera celui réalisant le classement des lignes extraites depuis INVENTORY selon la valeur du stock, double cliquez donc sur ce Dataflow pour le charger dans votre espace de travail.
Importez la table INVENTORY depuis les métadonnées externes de votre banque de données vers les métadonnées de votre référentiel puis utilisez cette table comme source dans DF_SPLW_PRODUIT. Cliquez sur la loupe pour obtenir un échantillon des lignes présentes dans INVENTORY :

Les lignes de INVENTORY sont structurées selon les trois champs suivants :
- TIME_KEY qui identifie le jour.
- PRODUCT_ID qui indique le produit concerné (identifiant unique).
- STOCK_LEVEL qui indique le niveau de stock du produit identifié par PRODUCT_ID au jour identifié par TIME_KEY.
Dans la bibliothèque d’objet de votre référentiel local, allez dans l’onglet « Transformations » pour trouver dans la catégorie « Plateforme » un composant Case à insérer dans votre flux :

Puis créez depuis votre banque de données DS_SPL_Warehouse un modèle de table appelé SPLW_BON_STOCKS qui servira de cible pour votre flux de données :
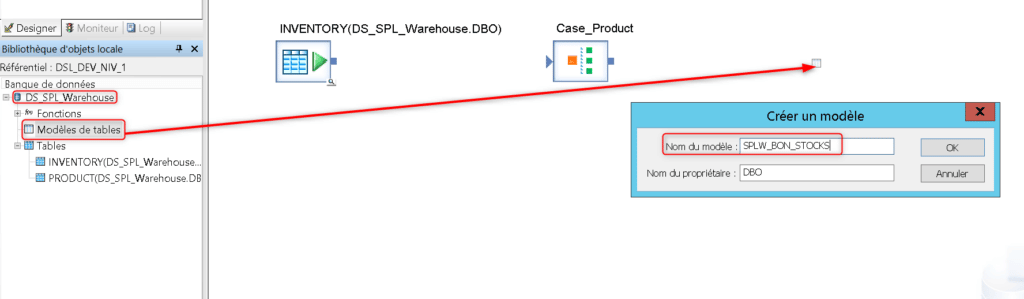
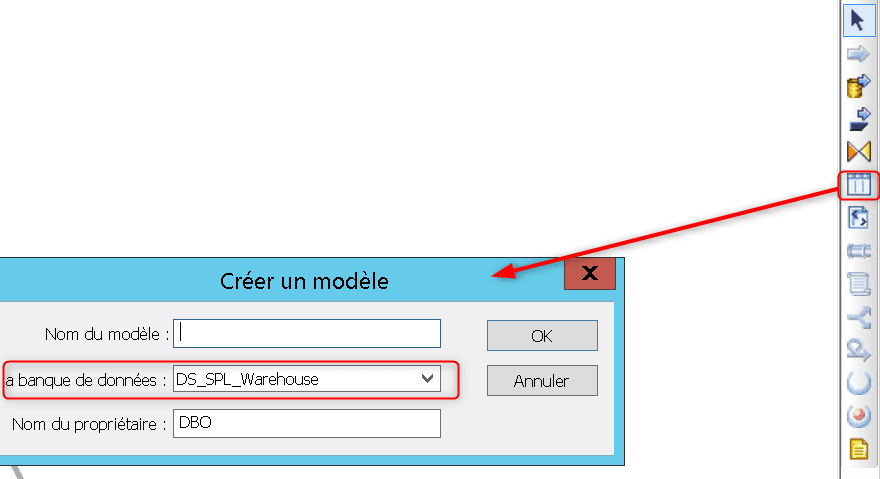
Lors du la première exécution de votre Job une nouvelle table sera crée dans votre base de données SPL_Warehouse selon la structure du flux d’entrée (noms, succession et types des champs). Lors de chacune des exécution suivantes cette table sera supprimée puis recrée en s’adaptant au changement de structure de son flux d’entrée, elle pourra ainsi servir de table de travail temporaire. Vous pouvez aussi créer une table temporaire de la manière suivante :
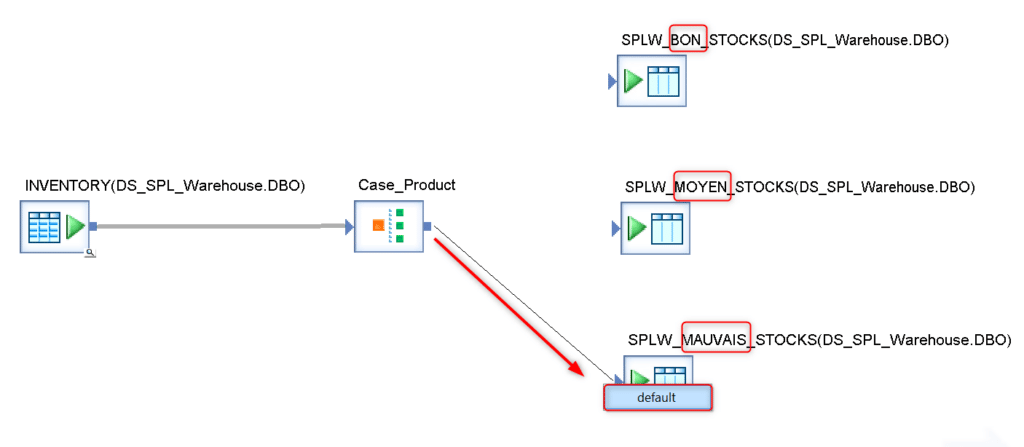
Ajoutez deux nouveaux modèles de table SPLW_MOYEN_STOCKS et SPLW_MAUVAIS_STOCKS puis cliquez sur la sortie du composant Case et glissez jusqu’à atteindre l’entrée de SPL_MAUVAIS_STOCKS. Choisissez cette sortie comme la sortie par défaut, elle sera empruntée si aucune des conditions testées dans la Case n’est réalisée :
Ouvrez le composant Case, la structure des lignes extraites depuis INVENTORY apparaît en haut. Ajoutez une nouvelle étiquette appelée « Case_Stocks_Bons », cette étiquette va vous permettre de définir une condition testée par votre Case sur chacune des lignes extraites :
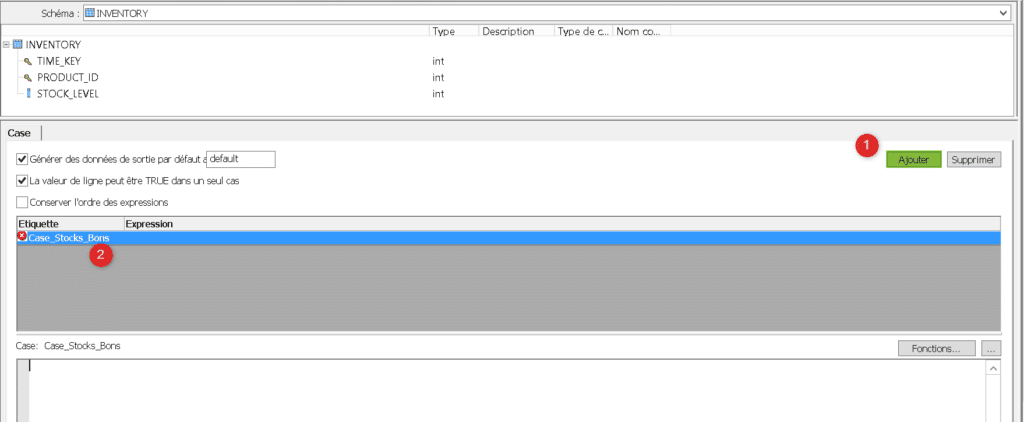
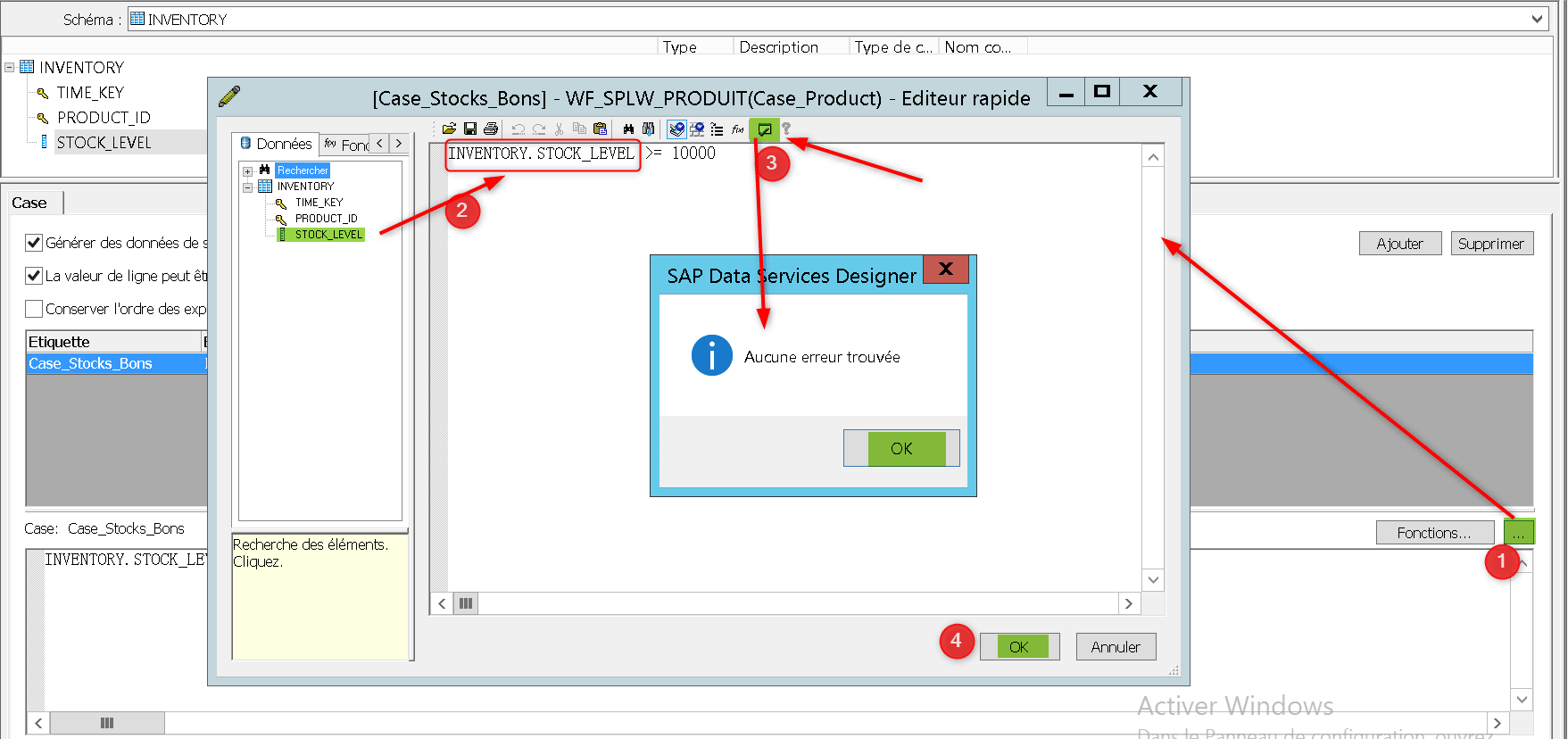
Pour définir une condition pour votre étiquette ouvrez le « Smart Editor » puis depuis l’onglet « Données » cliquez – déposez le champs STOCK_LEVEL sur lequel porte votre condition. Indiquez que la valeur de ce champs doit être supérieure à 10 000, ce qui constitue un bon stock pour le jour et le produit correspondant. Validez votre vue puis cliquez sur OK :
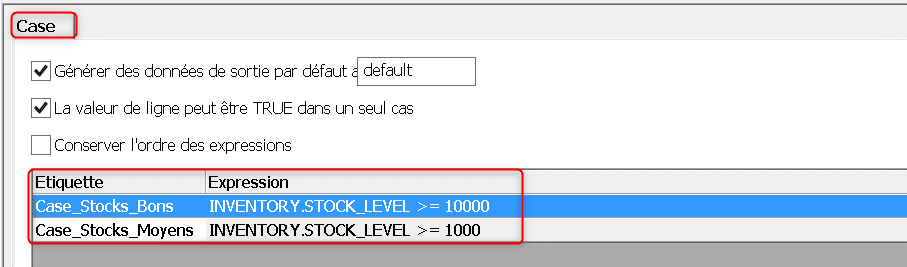
Définissez une nouvelle étiquette de condition pour tester si la ligne contient une valeur de stock moyenne, vous disposez maintenant de deux conditions testées sur chaque ligne d’entrée :
Dans la vue de votre Dataflow, créez deux nouvelles sorties de votre Case vers les modèles de table stockant les lignes ayant un stock moyen, puis bon. Indiquez à chaque fois laquelle des conditions écrites dans le Case doit être satisfaite pour que la ligne emprunte le flux :
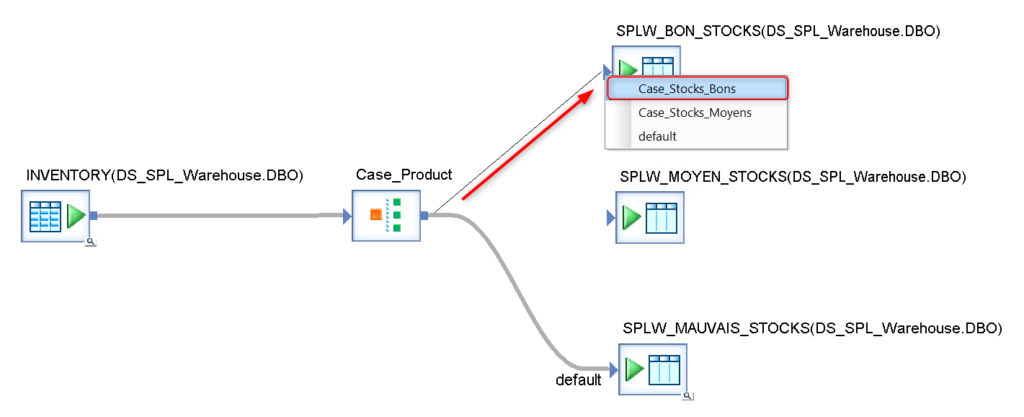
Les conditions que vous avez créé sont emboîtées dans l’ordre dans lequel elles apparaissent dans la Case. Pendant l’exécution si la valeur de stock d’une ligne est testée comme bonne (supérieure à 10 000) alors cette ligne est envoyée dans le flux 1 ci – dessous.
Si ce n’est pas le cas la deuxième condition (valeur de stock supérieure à 1000) est testée, et la ligne est envoyée dans le flux 2 si cette condition est réalisée. Enfin si aucune des deux conditions n’est satisfaite la ligne sera envoyée dans le flux par défaut, c’est-à-dire le flux 3 :

Après validation de la vue de votre Dataflow puis de votre Job, lancez l’exécution. Si elle se déroule normalement allez dans le log de suivi des lignes exécutées :

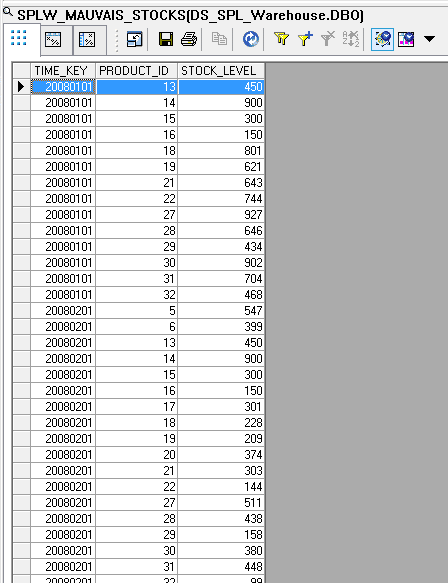
Vous pouvez voir le nombre de lignes chargées dans chacune des trois tables cibles selon le résultat de la condition testée dans le case pour chacune de ces lignes. Revenez dans la vue de votre Dataflow puis cliquez sur la loupe de la table cible SPLW_MAUVAIS_STOCKS pour obtenir un aperçu des données, vous pouvez y voir toutes les lignes avec valeurs de stock mauvaises (inférieures à 1000) :
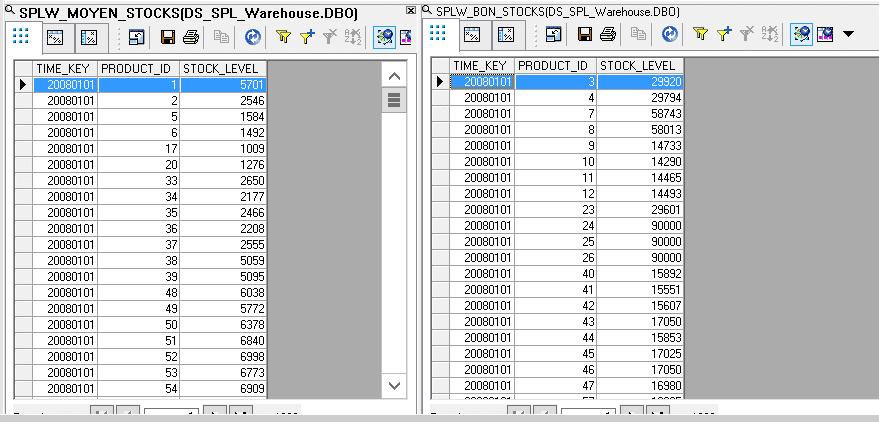
Enfin visualisez l’aperçu des données des deux autres tables cibles. Vous pouvez y vérifier que les lignes de SPLW_MOYEN_STOCK correspondent toutes à une valeur moyenne du stock (entre 1000 et 10 000) et que les lignes de SPLW_BON_STOCK correspondent toutes à une valeur bonne du stock (supérieure à 10 000) :
Vous savez maintenant comment utiliser le composant Case de Data Integrator pour classer vos données d’entrée selon plusieurs critères.

Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !