
Récupérer des données avec des fonctions personnalisées
Dans ce tutoriel vous apprendrez comment récupérer des données indexées dans une table en construisant des fonctions personnalisées (custom functions) prenant en premier paramètre une valeur de clé primaire et en deuxième paramètre le type d’information à ramener. Vous utiliserez ensuite les fonctions crées dans des traitements SAP Data Integrator.
Prérequis :
- Installation de SAP Data Services avec une version compatible de SAP Information Platform Services (IPS).
- Création d’un référentiel local. Voir ce tutoriel.
- Savoir créer un projet contenant un Job extrayant des données source depuis une base de données pour les transformer et les charger dans une autre base de données : principe de l’ETL (Extract, Transform, Load), voir ce tutoriel.
- Savoir utiliser des jointures sous SAP Data Integrator. Voir ce tutoriel.
Version : SAP Data Services 4.2 SP 10
Base utilisée : Sous Microsoft SQL Server 2012
Principe :
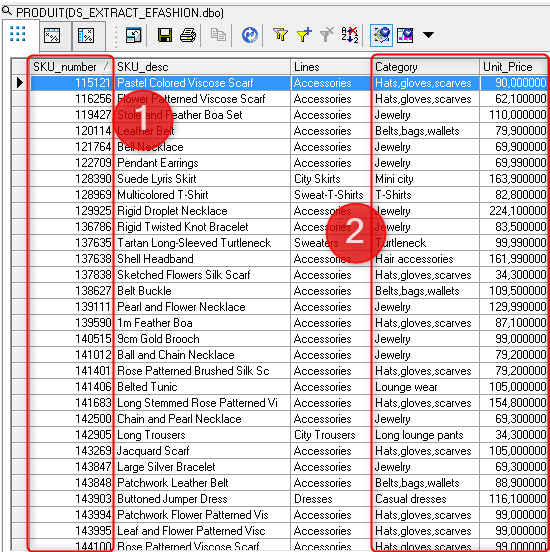
Vos fonctions personnalisées iront chercher leurs données dans la table « PRODUIT » ci – dessous afin de les combiner avec des données d’une autre table « MAGASIN ». Ces tables contiennent des données issues de l’Univers efashion installé par défaut avec SAP BusinessObject. Le paramètre d’entrée de ces fonctions sera la clé primaire « SKU_number » de la table PRODUIT (1) et les paramètres de sortie seront « Category » pour la première fonction et « Unit_Price » pour la seconde :
Afin de créer ces fonctions allez dans la bibliothèque d’objets de votre référentiel local et cliquez sur « Fonctions » :
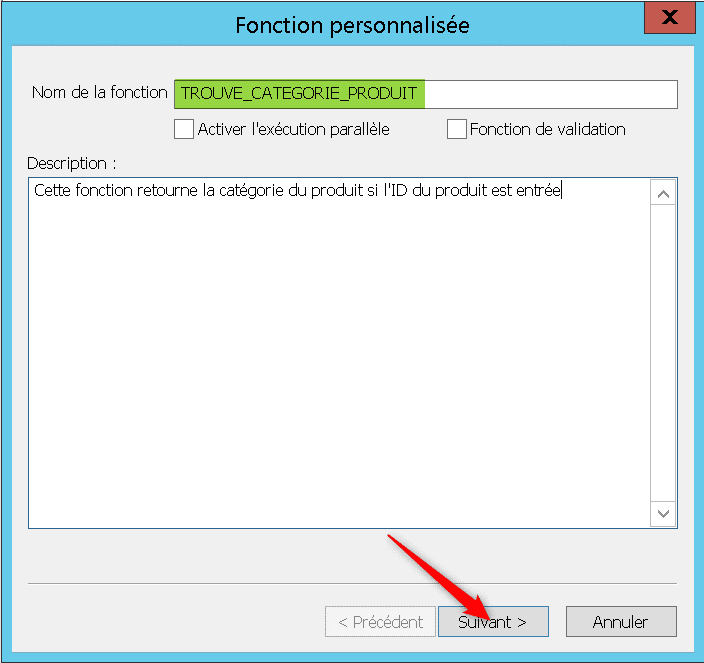
Faites un clic droit sur l’écran des fonction puis cliquez sur « Nouveau », vous accédez à la fenêtre ci – dessous de création de fonction. Indiquez le nom de la fonction puis une description de celle – ci. Cette fonction permettra de récupérer la catégorie du produit pour une valeur de clé donnée :
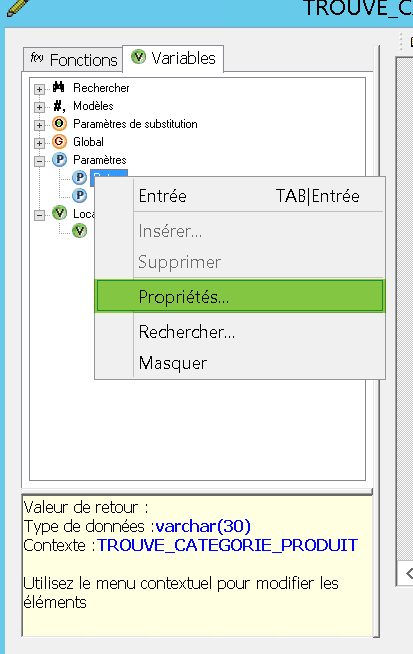
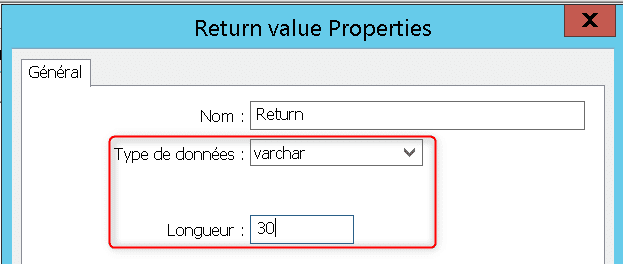
Dans la liste des variables de la fonction faîtes un clic droit sur « Return » puis allez dans ses propriété. « Return » est un paramètre qui stocke la valeur de retour de la fonction :
Indiquez que la valeur retourné par votre fonction est de type « varchar » et de longueur 30 puis validez par « OK » :
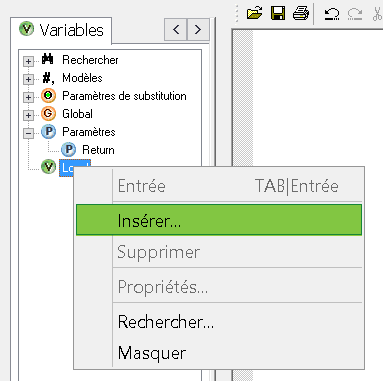
Par un clic droit insérez une variable locale. Cette variable ne pourra être affectée qu’à l’intérieur de la fonction et permettra d’en stocker les résultats intermédiaires :
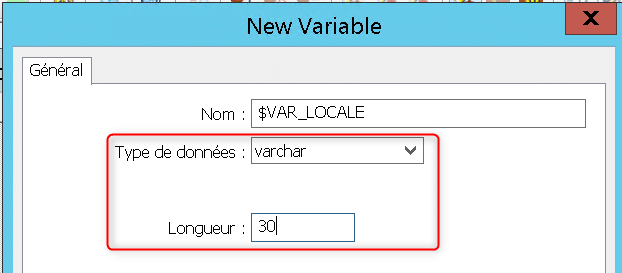
Indiquez que la variable locale se nomme « $VAR_LOCALE », est de type « varchar » et de longueur 30 :
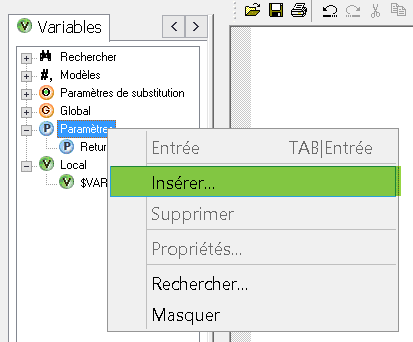
Ajoutez un paramètre d’entrée à la fonction. Lorsqu’elle sera appelée avec ce paramètre la fonction récupérera sa valeur si son type est correct (sinon une erreur sera levée). Des calculs pourront alors être effectués à partir de ce paramètre au sein de la fonction :
Le paramètre d’entrée « $ID_PRODUIT » est destiné à récupérer la valeur de la clé entière de la table « PRODUIT », afin de retourner une autre valeur de la table « PRODUIT ».. Son type doit donc être « int » :
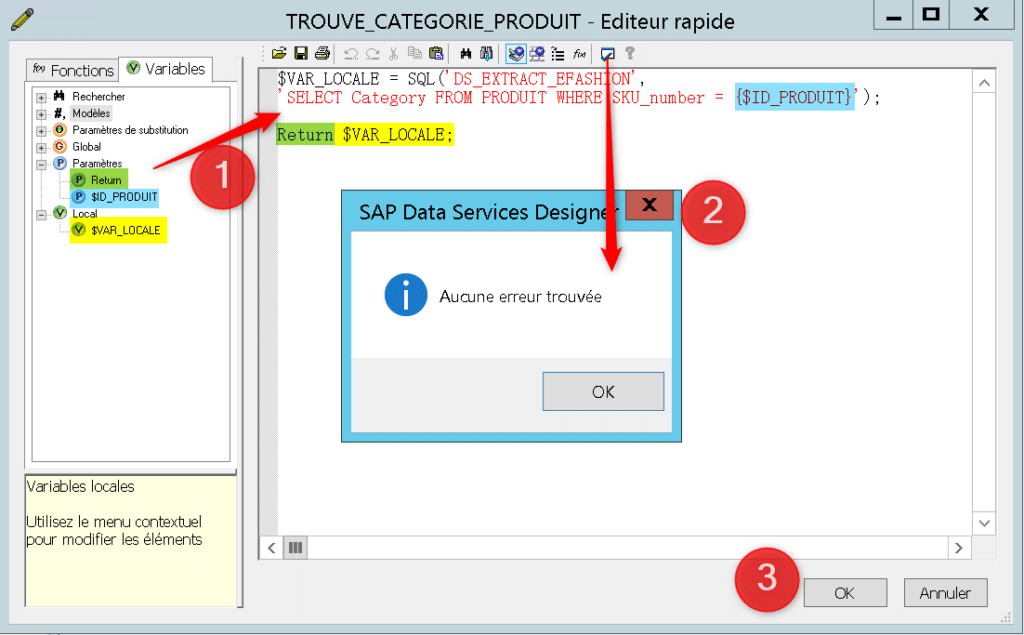
Affectez à la variable locale le résultat de la requête SQL d’extraction de la catégorie du produit depuis la table « PRODUIT » pour une valeur de sa clé égale au paramètre d’entrée « $ID_PRODUIT » de la fonction. Pour celà cliquez – glissez (1) les paramètres et variables utilisées. Validez ensuite la syntaxe de la fonction (2) puis validez par OK (3) :
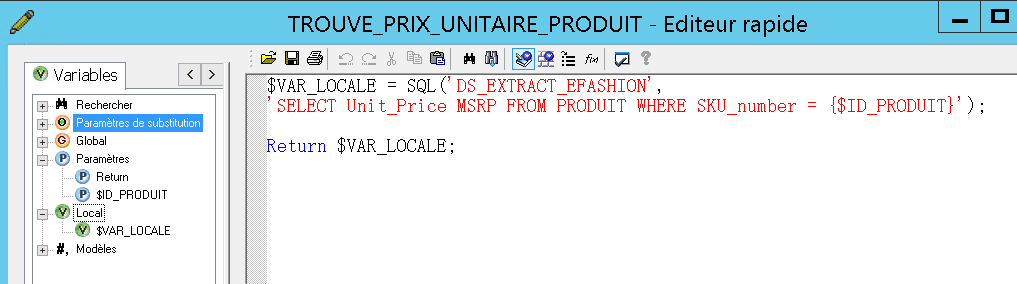
Par la même procédure que ci – dessus, créez une fonction personnalisée permettant de récupérer le prix unitaire depuis la table « PRODUIT » pour une valeur donnée de clé. Le type de sortie doit cette fois être « double », mais attention pour la variable locale vous devrez utiliser le type decimal(10, 2) car le type double n’existe pas en Microsoft SQL Server 2012. Ce type sera implicitement converti en double lorsque la valeur de la variable locale sera affectée au « Return » :
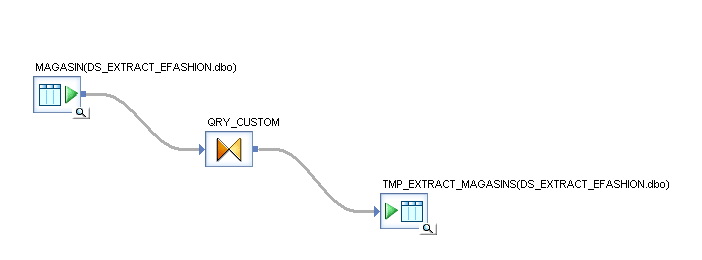
Créez un JOB contenant le Dataflow suivant, extrayant des données depuis la table « MAGASIN » avec pour cible un modèle de table « TMP_EXTRACT_MAGASINS » et une transformation des données au sein du Query « QRY_CUTOM » :
Ouvrez le Query, et créez un groupement des lignes d’entrée selon la clé produit « SKU_number », le nom du produit « SKU_desc » et l’année :
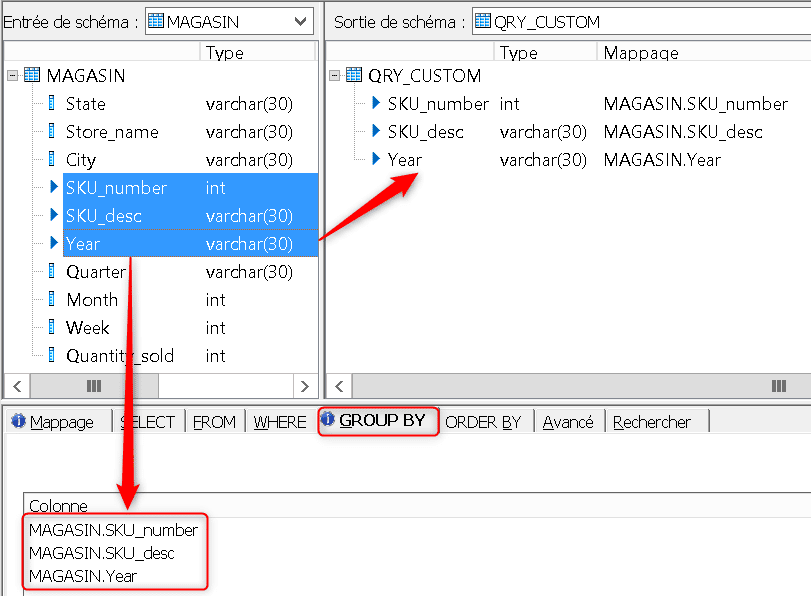

Ajoutez deux nouvelles colonnes de sortie nommées « Category » et « Revenue ». Ecrivez « Revenu » comme une somme
des quantités vendues sur chaque groupement des valeurs de clé et nom du produit et de l’année :
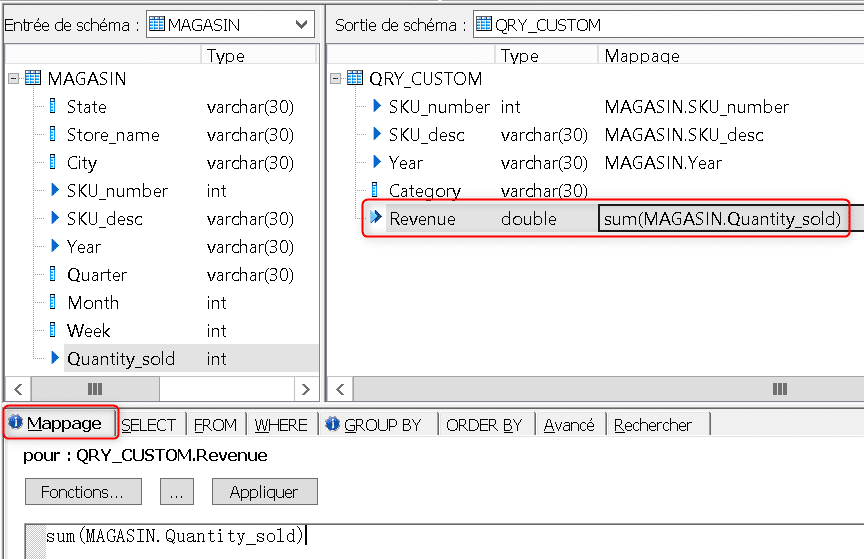
Depuis la fenêtre de mapping de la colonne « Category » cliquez sur « Fonctions ». Depuis « Fonctions personnalisées » les deux fonctions que vous avez crée sont visibles :
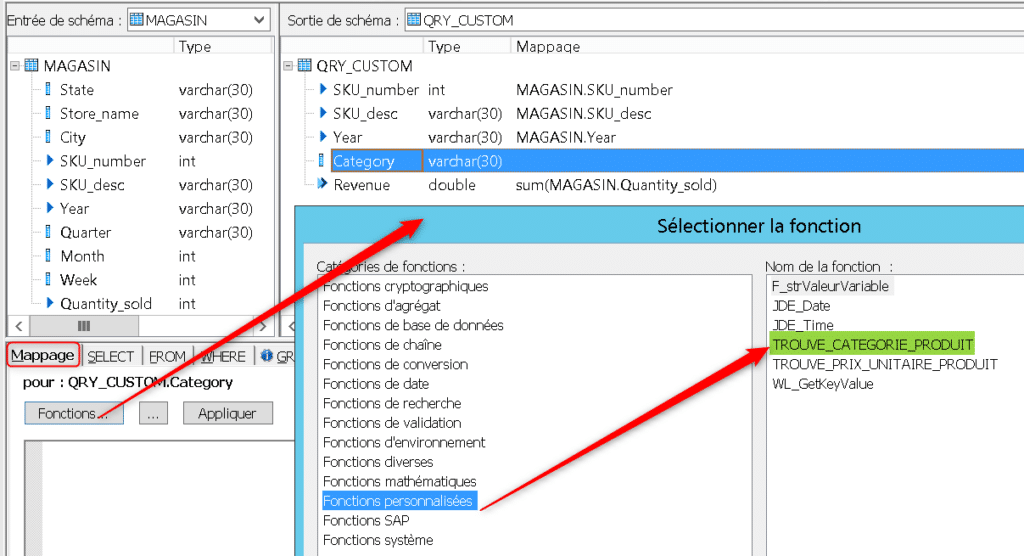
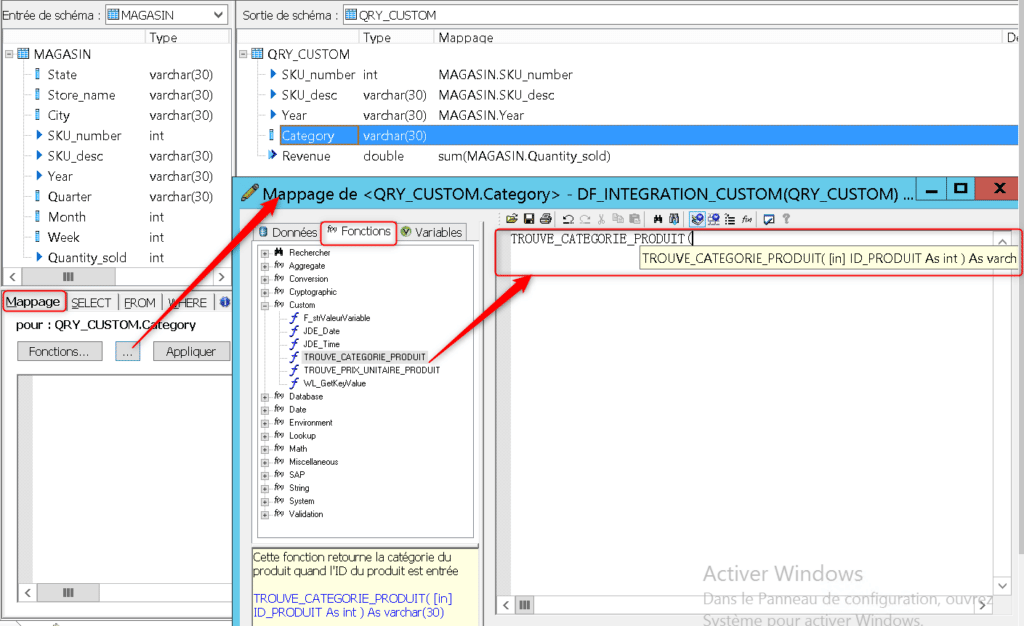
Nous allons plutôt utiliser l’éditeur de fonction qui permet de retrouver les données, fonctions et variables nécessaires au mapping de « Category ». Cliquez glissez le nom de votre fonction, un cadre apparaît avec le template de la fonction, c’est à dire ses paramètres d’entrée et de sortie. Si vous ne respectez pas leur type une erreur sera générée :
Ajoutez au mapping de « Revenue » une multiplication de la quantité vendue par le retour de la fonction donnant le prix unitaire. La fonction sera reconnue si vous en tapez les premières lettres. Vous obtenez ainsi, pour chacun des produits, les revenues générés pour chacune des années :
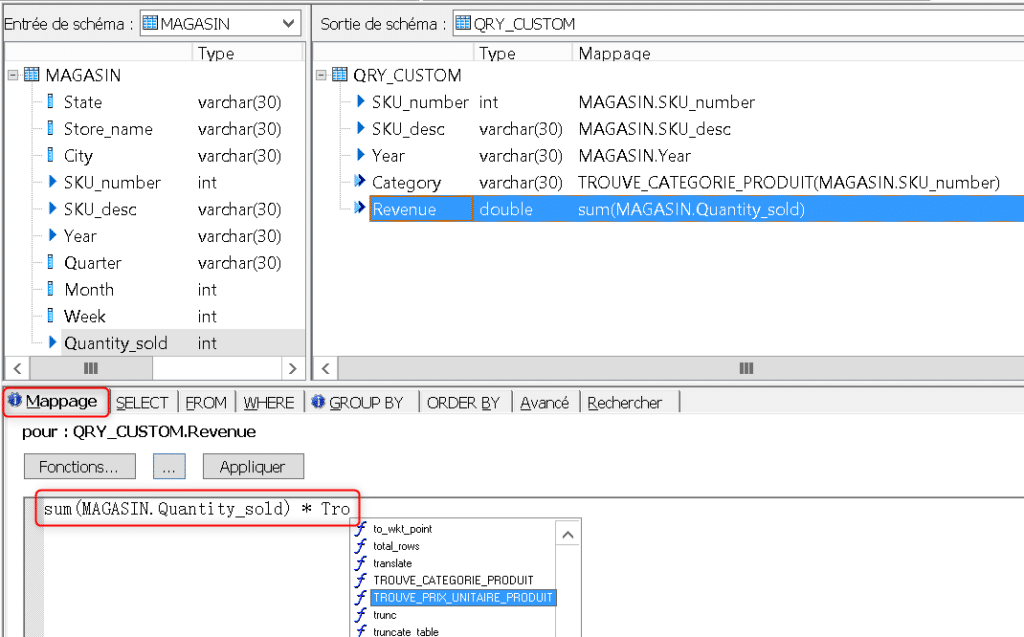
Voilà le mapping que vous devez obtenir pour vos colonnes de sortie, pensez à valider votre Query :
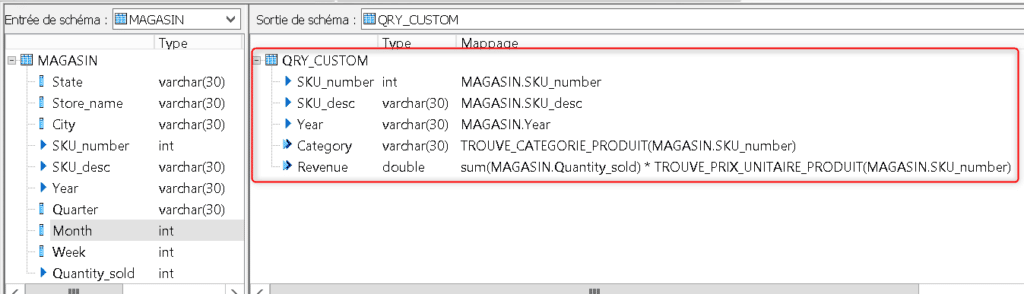
Validez votre Dataflow puis votre Job et lancez son exécution. Vous obtenez en table cible le contenu suivant. Dans le cadre de droite sont visibles les valeurs de retour des fonctions utilisées pour récupérer Catégorie du produit et revenu :

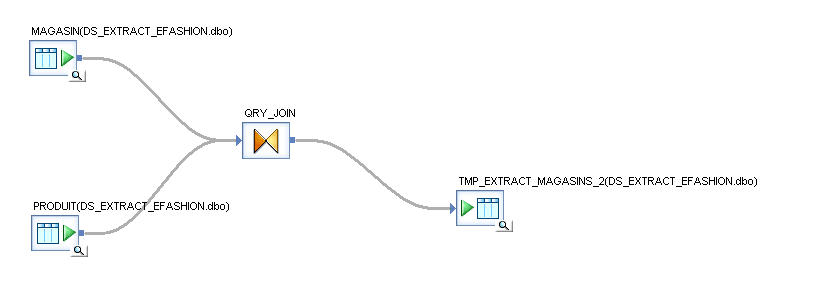
Si vous avez bien lu le tutoriel sur les jointures vous pouvez réaliser à ce stade que vous auriez pu développer exactement la même chose avec le Dataflow suivant réalisant une jointure entre les tables « MAGASIN » et « PRODUIT » selon la clé produit. Nous pouvons observer que l’utilisation de fonctions permet plus de concision.. Une table et une jointure en moins dans le cas présent. Mais comme nous le verrons plus loin il y a un prix à payer pour cette économie.
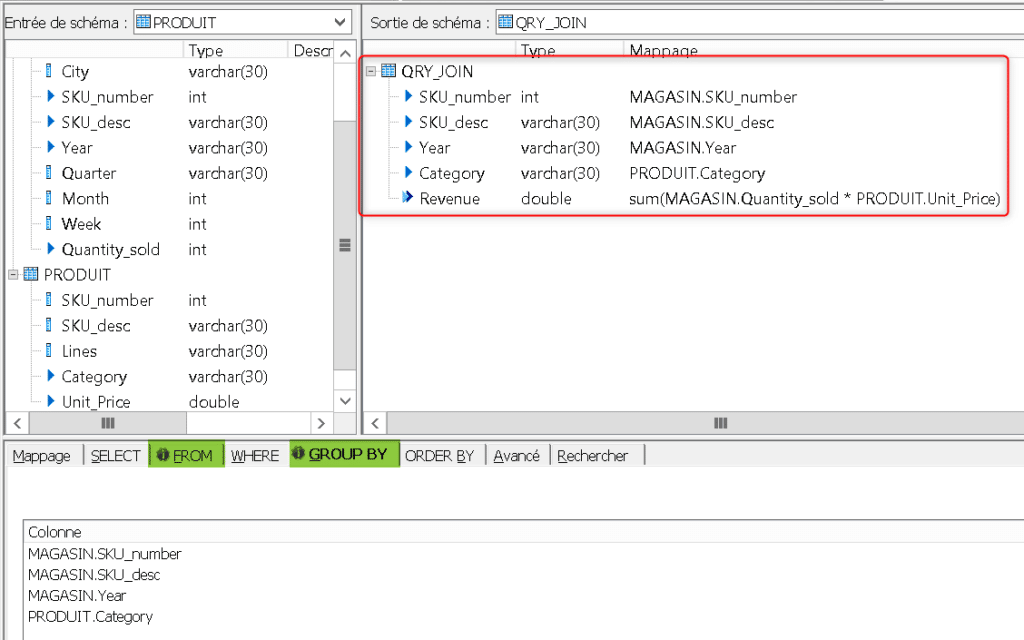
Voilà le contenu de « QRY_JOIN » qui réalise la jointure et le groupement. les colonnes de sortie « Category » et « Revenue » qui étaient obtenues en valeurs de retour de fonction prédéfinies sont maintenant mappées depuis le schéma d’entrée :
Nous allons montrer ici le prix de la concision apportée par l’écriture de fonctions allant directement chercher des résultats dans des tables. Ci – dessous vous pouvez voir le log d’exécution du traitement utilisant les fonctions personnalisées, la durée d’exécution est de 9,7 s :
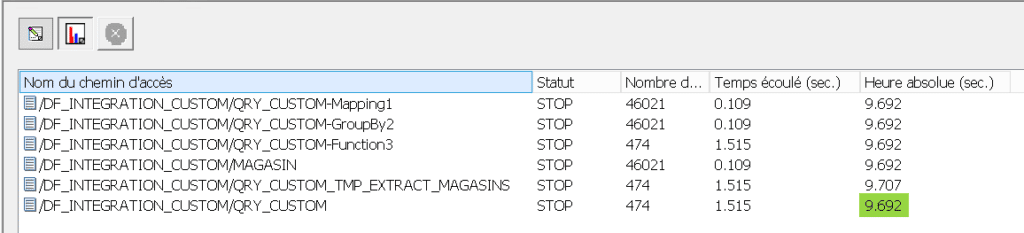
Voici le log d’exécution du traitement utilisant la jointure entre « PRODUIT » et « MAGASIN », la durée d’exécution n’est que de 7,2 s :

Une première raison à cette différence est du au fait que le traitement utilisant les jointures ne lance, pour chacune des valeurs de clé produit, qu’un seul appel vers la table « PRODUIT » alors que le traitement utilisant les fonctions le fait deux fois (une fois pour chacune des fonctions).
Une autre raison, qui sera d’autant plus marquée que le nombre et le volume des données utilisées est grand, est que SAP Data Integrator est conçu pour optimiser le contenu de ses Dataflows, des requêtes décomposées dans un Query seront ainsi traitées de manière optimale. Il faut donc éviter d’abuser de l’utilisation de fonctions personnalisées ou de SQL brut pour appeler des données.
Vous savez désormais comment utiliser des fonctions personnalisées sous SAP Data Integrator.

Laisser un commentaire
Il n'y a pas de commentaires pour le moment. Soyez le premier à participer !